Keywords
machine learning, synthetic data, smoking, tobacco, adolescent girl, algorithm, behavioral science
machine learning, synthetic data, smoking, tobacco, adolescent girl, algorithm, behavioral science
This version is a response to viewer comments. Additional details and references have been added to the Introduction section. Additionally we have clarified the secondary analyses performed, added the notable results, and expanded on a few points in the Discussion section.
See the authors' detailed response to the review by Jennifer M. Murray
See the authors' detailed response to the review by Ruoyan Sun
Machine learning (ML) is a discipline at the intersection of data science and artificial intelligence with a focus on building algorithms to make predictions without requiring explicit programming to do so1. The approach involves building a model using sample training data. These methods are increasingly being applied to support evidence-based decision making across a wide range of fields, including global health. Here we report our experience applying ML to generate programmatic insight from data collected for a rigorous impact evaluation.
Rising tobacco use among adolescents in low and middle-income countries (LMICs)i and increasing tobacco use among girls relative to boysii highlight the need for interventions to prevent and reduce tobacco use among adolescent girls. Non-cigarette tobacco products are contributing to the narrowing gender gap,iii and surveys suggest shisha use is now more prevalent among girls than boys in Ghana, although with significant regional variation.iv As external evaluators of a social marketing program in Ghana focused on discouraging tobacco use among adolescent girls, we conducted a stepped wedge cluster randomized trial and panel survey of 9000 girls aged 13–19 in select neighborhoods of Accra and Kumasi over twelve months of 2021–2022. A secondary objective was to provide additional behavioral insights on the pathways influencing smoking behavior among teenage girls in Ghana and to identify programmatic opportunities for impact. Although a formative research phase with qualitative interviews informed by the behavioral science literature was conducted to support this objective2, we were interested to explore how recent advances in ML techniques might be applied to our panel survey data to generate additional insights related to the predictors of smoking initiation and to compare and contrast findings from these two approaches.
Although our study had a relatively large sample, smoking behavior was quite rare. Only 1.6% of girls reported having ever tried smoking (defined as cigarette or shisha use) at baseline and 0.1% having smoked in the past 30 days. We wanted to think more creatively about ways to profile potential smokers in this population beyond basic demographic slices of the sample. Our objective was to first build an algorithm that would predict which girls are more likely to be smokers and then identify which factors are most important to make those predictions. In this research note we describe how we explored several ML methods to build a classifier model and then applied a ML explainability method to profile the most important predictors of smokers using different smoking definitions, as well as different data subsamples.
Data collection for the step wedge evaluation included a survey of all 9000 girls over four rounds—Baseline (before any implementation), Midline 1 (after the first period of implementation), Midline 2 (after the second), and Endline (after all areas had been activated). Participants aged 13–19 were recruited through multi-stage sampling in which neighborhood clusters in Accra and Kumasi were first randomly selected for the study, and then households within each cluster were systematically approached through a community mapping process until the target number of adolescent girls willing to participate in the study were identified. To be considered eligible for the study, girls had to have access to a phone and had to intend to remain at their residence over the subsequent year, to enable enumerators to reach them at future rounds of the panel survey. The questionnaire was informed by the formative research and a smoking-oriented theory of change and comprised about 100 questions covering: background and demographic information; social context, confidence, and self-efficacy; sources of influence on girls’ decisions and actions; tobacco perceptions and norms; tobacco use, opportunity, and refusal; and program exposure and perceptions. Tobacco use questions were adapted from the Global Youth Tobacco Survey.v The questionnaire was reviewed for face validity with the program team and portions were piloted with 396 adolescent girls during the formative research phase2. Most responses were binary or Likert scales of 1 to 4 that were recoded to binary (agree vs. disagree, likely vs. not likely) for this exploratory exercise. Several indices of multiple survey items that were confirmed to have high internal consistency served as indicators of intermediate outcomes in the impact evaluation; however, for this application of ML techniques survey items were maintained as individual variables. Ethical review and approval for the evaluation study were provided by Innovations for Poverty Action IRB (protocol #15798) and the Ghana Health Service Ethics Review Committee (GHSERC: 003/11/20). Written informed consent to participate in the study was obtained from participants aged 18 years or older. For younger participants, written parental consent was first obtained followed by written assent of the adolescent.
Initially, we trained a basic Random Forest classifier using the baseline data to identify girls who have ever smoked, which performed well in terms of accuracy (Table 1). Accuracy is defined as the proportion of all girls who are correctly classified as either smokers or non-smokers (Figure 1).
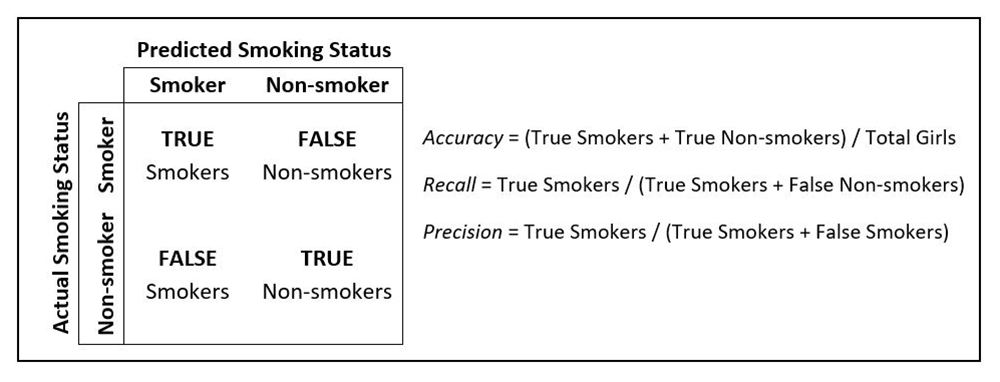
To optimize our baseline model, we chose to focus on increasing the recall metric, rather than just accuracy. Recall is a measure of the model's ability to correctly identify actual smokers; a high recall value indicates that the model is able to identify most girls who smoke, while a low recall value suggests that the model is missing a significant number of smokers. Accuracy, which is affected by the low prevalence of smoking in our data, can bias the model towards classifying most individuals as non-smokers. Therefore, we were more concerned with correctly identifying those who did smoke to ensure effective programmatic targeting towards likely smokers, even if it meant that some non-smokers were mistakenly identified as smokers.
Additionally, we focused on improving the model’s precision. If the precision of the model is low, it means that the model is classifying many individuals as smokers even though they are not, which could result in potentially unnecessary or less well-targeted interventions. Therefore, improving precision helps to reduce targeting of non-smokers and ensures that the resources allocated to smoking interventions are still used effectively and efficiently.
With the objective of optimizing the recall and precision, we evaluated the following ML approaches using the “imbalance-library” Python package3 (which is built upon the “scikit-learn” ML library) to determine which method produced the optimal outcome:
RandomOverSampler: This technique works by randomly oversampling the minority class (smokers) in the dataset, i.e., it generates additional random samples of the minority class to balance the class distribution.
ADASYN (Adaptive Synthetic Sampling)4: ADASYN works by generating synthetic samples of the minority class based on the density of the minority class in the feature space and the distance between minority samples. The goal is to increase the number of samples of the minority class in the training data while maintaining a balanced representation of the classes in the feature space.
SMOTE (Synthetic Minority Over-sampling Technique)5: Like ADASYN, SMOTE works by generating synthetic samples of the minority class, but instead of generating samples based on the density and distance of the minority class, it generates samples based on the k-nearest neighbors of the minority samples. In this study 5 k-neighbors were used.
Class weighting: This method assigns higher weights to the minority class, encouraging the algorithm to pay more attention to the minority class and make better predictions.
Hellinger Distance as a Tree Split Criterion6: Hellinger distance is a measure of the difference between two probability distributions. In decision tree algorithms, Hellinger distance can be used as a criterion for splitting nodes in the tree, to determine the most informative split that maximizes the difference between the classes in the feature space. Using Hellinger distance as a split criterion can improve the accuracy of decision tree algorithms in imbalanced classification tasks by giving more attention to the minority class.
We ultimately selected the SMOTE technique of generating synthetic data for training the classification algorithm because it optimized its performance in terms of recall and precision (Table 1).
After successfully building a high-performing classification model, our goal was to build a profile of girls who smoke. However, ML models are often referred to as "black boxes" because they can be difficult to interpret and comprehend. This means that the model might make accurate predictions, but it's not clear how it arrived at those predictions or why a particular prediction was made.
To gain more transparency, we utilized the technique of feature importance. This method explains predictions made by the model by identifying which features or input data had the most significant impact on those predictions. Essentially, it helps us understand which characteristics have the most influence in predicting a girl to become a smoker. By calculating feature importance we aimed to generate greater insight into how the model arrived at its decisions and to rank the most important variables. We determined whether an important feature is a risk for or protective against smoking based on the direction of that variable’s association with the smoking outcome in our data.
To determine the profiles of girls most likely to smoke, we trained our model by using the following combinations of target outcomes and input variables from our survey data:
Model #1: Predicted outcome: reported ever tried smoking at baseline.
Model #2: Predicted outcome: reported having smoked during the previous month at endline.
Model #3: Predicted outcome: among non-smokers at baseline, reported ever tried smoking at endline.
As a secondary analysis we looked at these same combinations within sub-groups of respondents, including younger (13–15) vs. older girls (16–19) and Accra vs. Kumasi, to support interpretation of findings and identify heterogeneity in predictors. We also analyzed additional combinations of data inputs on these predicted outcomes at different time points for robustness.
Model #1 (Table 2) differentiates between girls based on smoking history prior to the study. The results highlight that girls who had ever tried smoking report different social settings and experiences at present than non-smokers. They are more likely to have regular phone access, recently attended a party, and/or been recently offered alcohol, which suggest more independence and social activity. They are also more likely to think their close friends have tried shisha, that their friends would approve of them smoking shisha, and to say that they would not likely refuse an offer of shisha from friends. Several indicators included in the evaluated program’s theory of change, particularly those related to girls’ confidence in expressing preferences to friends, were not important to classifying likely smokers.
Given that smoking in this population is rare and infrequent, Model #2 (Table 3) identifies which factors are most important to differentiate recent smokers from recent non-smokers. Endline responses were used given very few recent smokers at baseline. Recent smokers are more likely to be older and live in the capital Accra and report lower parental influence than non-smokers, another sign of greater independence. They are more likely to report that smoking is common among their peers and that they would accept an offer to smoke from friends, and less likely to perceive shisha as harmful. The belief that people who say no are admired by others is one of the top factors predictive of being a recent smoker; this may suggest positive views of smoking as demonstrating independence or rebelliousness against norms.
From Model #3 (Table 4) we profiled the small number of girls who were non-smokers at baseline but reported they had tried smoking by endline, in order to identify which factors are most important to set them apart from girls who remained non-smokers during the study period. We see that age and phone access were most important to subsequent smoking initiation, which suggests that these girls may already have had more independence and connectedness than other non-smoking girls. The girls that started smoking within the study period were also more likely to perceive that most social activities for girls their age involve shisha and that most girls their age have tried shisha, which suggests that they are also experiencing or perceiving a different social environment at baseline than other non-smokers. And these girls are more likely to report their friends have influence on their decisions, and less likely to report parent influence than other non-smokers, which suggests they might be more susceptible to social opportunity and persuasion.
In secondary analyses of Model 3, living in Accra and thinking other girls smoke shisha were the most important factors for smoking initiation among younger girls (13–15) who were non-smokers at baseline. Having friends that influence decisions was less important, and school status was one of the least important, likely because very few younger girls are not in school. Among older girls, having friends or parents who influence decisions were the most important factors. This suggests that the spaces and behaviors girls are exposed to may be more relevant for smoking initiation among younger girls, whereas interpersonal influence matters more among older girls.
We report here a novel application of ML techniques to generate insights around a behavior that is still relatively rare among urban teen girls in Ghana. Creating synthetic data through the SMOTE technique created a more balanced training data set for the classifier, and by opening up the black box of the algorithm we learned which features are most important towards predicting girls likely to be smokers.
While very few girls in Ghana have tried smoking, even fewer report having smoked in the previous 30 days. Models 1 and 2 suggest both groups are more likely to be older and have the freedom to attend social events where they may be exposed to smoking opportunities or behaviors that shape their perceptions of norms among peers. Living in Accra, the more cosmopolitan and diverse of the two study cities, was also common among both groups. However, a perceived higher prevalence of cigarette smoking and willingness to accept cigarettes from friends are distinctively strong predictors of recent smokers. This may reflect that shisha is more commonly experimented with among girls this age and is more likely to be smoked on an infrequent basis (less than monthly). For that reason, most strong predictors of ever having smoked reflect beliefs about shisha, whereas recent smokers who smoke cigarettes, while still the minority, may have particularly strong and distinctive views on cigarette smoking. Other distinctively strong predictors of recent smoking include reporting low influence of parents and expressing admiration for people who are willing to go against trends. Parents in Ghana are generally highly protective of their teenage girls and there is a strong social norm against smoking2; these findings may reflect the absence of such parental figures in smokers’ lives, or their willful rebellion against them.
Model 3 supports that changes in independence and the social environments shaping girls’ opportunities to smoke do in fact precede initiation and experimentation. Cross-sectional surveys can support associations between smoking behavior and social environment; the Model 3 classifier leverages survey data from two timepoints to highlight the pre-existing differences among non-smoking girls that are most predictive of subsequent smoking initiation. Among younger girls, this may reflect different home environments, where girls have more mobility and less parental oversight, putting some girls at more risk of smoking opportunities. These differences may also explain why older age is such a strong predictor of smoking, as adolescent girls are often given more freedom to attend social events and activities as they age. Furthermore, many girls in urban Ghana enroll in a boarding school for their Senior High School (SHS) education where they may gain exposure to girls from less sheltered backgrounds who may influence subsequent opportunities for smoking2.
Such insights about the relative importance of different features to a target behavior can be valuable input for program planning and outreach that is responsive to a specific population and context. This is especially true in the case of programs aimed at smoking prevention, given that smoking in teens is addictive and the literature suggests that people who avoid smoking in adolescence are unlikely to ever startvi. Better understanding of the risk factors for recent and future smoking behavior, and in particular the role of the social environment, can suggest programmatic opportunities for targeting adolescents most at risk or exploring more promising programmatic directions, such as reshaping the environments they are exposed to.
Although the smoker profiles generated through this approach are limited by the inputs we provide the machine, i.e., our survey data, they were largely consistent with our formative qualitative research findings around influences on girls’ behavior in urban Ghana2. The large sample size of this study obtained through cluster randomized sampling is one of its strengths, although there are potential limitations related to collecting data on sensitive topics from adolescent girls, as discussed in that study2. Data collection tools in both cases were informed by insights from the tobacco literature and behavioral science; we believe grounding survey data collection in strong behavioral science theory strengthened the utility of the ML outputs and resulted in better alignment of findings with more in-depth qualitative research techniques. This novel application of ML techniques demonstrates the potential synergism between data science and behavioral science to generate insights about predictors of behavior and highlights the importance of basing quantitative data collection in behavioral theory, especially if opportunities for rich qualitative investigation are limited in other settings.
| Views | Downloads | |
|---|---|---|
| Gates Open Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with Gates Open Research
Already registered? Sign in
If you are a previous or current Gates grant holder, sign up for information about developments, publishing and publications from Gates Open Research.
We'll keep you updated on any major new updates to Gates Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)