Keywords
Clinical trial protocol, risk, natural language processing, uninformativeness
Clinical trial protocol, risk, natural language processing, uninformativeness
The goal of conducting a clinical trial is to produce evidence that can inform clinical and policy decisions. Each year, more than half a million clinical trials are run1, each one seeking to gather information on an intervention such as a drug, device, or behavioral intervention.
However, the majority of clinical trials do not prove or disprove a hypothesis2. A 2022 study of 125 clinical trials in heart disease, diabetes, and lung cancer by Hutchinson et al.3 found that just over a quarter ended informatively, and other estimates are even lower4.
The Declaration of Helsinki, a key set of ethical principles on clinical trials, states that “Medical research involving human subjects may only be conducted if the importance of the objective outweighs the risks and burdens to the research subjects”5. In other words, research is considered unethical if there is no benefit to science.
In 2019, Deborah Zarin and colleagues addressed the problem of uninformative clinical trials in the Journal of the American Medical Association6. Zarin et al. stated that for a trial to be informative, it must fulfill five conditions:
1. The study hypothesis must address an important and unresolved question
2. The study must be designed to provide evidence related to this question
3. The study must be feasible
4. The study must be conducted and analyzed in a scientifically valid manner
5. The study must report results accurately and promptly.
When a trial does not fulfill all of the above conditions, it is likely to be uninformative. That means that the time and money spent on the trial, not to mention the subjects’ good intentions on enrolling, were wasted.
The most common reason why trials end uninformatively is due to underpowering, or inadequate sample size. Other common reasons are safety and commercial factors7,8.
At the stage of drafting the trial protocol, it is possible to identify a number of indicators of a high risk of uninformativeness. These include a smaller than typical sample size, a lack of statistical analysis plan, use of non-standard endpoints, or the use of cluster randomisation. Low-risk trials are often run by well-known institutions with external funding and an international or intercontinental array of sites. These indicators can be referred to as features or parameters.
In contrast to easily measured metrics, such as cost, informativeness is a somewhat subjective and even philosophical concept. One definition is that of “moral efficiency”: does the trial improve clinical practice?
There are a number of ways of quantifying informativeness. For example, Hutchinson et al. measured informativeness in a retrospective longitudinal study, by following up trials longitudinally and identifying events that happened after trial completion, such as whether the trial influenced clinical practice guidelines, or was cited as part of a high-quality systematic review3. These indicators can be subject to bias: a trial with industry funding is more likely to be cited, all other factors being equal, but may not necessarily be more informative. Likewise, a trial which shows that a drug is unsafe may not change guidelines or be cited, but prevents further uninformative trials being run, and is therefore informative. Hutchinson et al. acknowledged that the longitudinal technique is limited to a retrospective ‘thermometer’ rather than for prospective use.
In this paper, we use the concept of the “risk of ending uninformatively”, rather than the uninformativeness directly. An expert reviewer reads a protocol and classifies it as high, medium, or low risk of ending uninformatively, based solely on the content of the document. This approach is less data-driven and also subject to human biases, but does not require a longitudinal study to implement.
A number of initiatives have been introduced to assist investigators in assessing the risk of a clinical trial. For example, the British National Institute for Health and Care Research has published a risk assessment tool as part of their Clinical Trials Toolkit9. In 2017, a team funded by the Wellcome Trust developed a single-page clinical trials risk assessment tool10, and in 2019 the company Mediana Inc released an R package for clinical trial simulations with an aim of reducing trial risk11.
New methods for simulating trials at the planning stage are becoming more popular, such as calculating the “assurance” of a trial, introduced by O’Hagan et al. in 2005, which is the unconditional probability that the trial will yield a positive outcome12. The assurance method can be used to choose a sample size, and has been implemented as an R package13. In 2013, Wang et al. proposed a similar Bayesian method for calculating what they called the ‘probability of study success’ (PrSS)14.
There have also been proposals to use probability distributions for making "go/no-go" decisions at clinical milestones such as the end of Phase I, IIa, or IIb15. In 2009, Rosen et al. proposed the use of process maps throughout the trial to monitor if the trial is being conducted according to the Standard Operating Procedures (SOP)16.
In 2018, Wong et al. published an analysis of 406,038 entries of clinical trial data, and calculated trial success rates by trial phase, pathology, year, industry, and other factors. They found a number of interesting patterns, for example, that trials that used biomarkers as part of their selection criteria have higher overall success probabilities than trials without biomarkers17.
In 2022, a team at the Tufts Center for the Study of Drug Development analyzed 187 protocols and subsequent trials, and found that oncology and rare disease protocols have significantly longer clinical trial cycle times and face challenges in recruitment and retention18. Phase III oncology trials are particularly troublesome, as they often deal with very small differences between arms. 62% of Phase III oncology trials fail to deliver results with statistical significance19.
As an analogous metric to trial risk, there is also trial complexity. There are several numerical tools for estimating the complexity (and, by extension, cost) of clinical trials using simple scoring mechanisms in the style of the Apgar score, which is a well-known formula for evaluating the health of newborn babies20–22.
In recent years, Natural language processing (NLP) tools have disrupted a number of industries where large unstructured text documents are commonplace23,24. The advent of models such as convolutional neural networks and transformer neural networks has enabled the development of AI systems which can understand complex natural language documents, such as contracts, or insurance claims25–28. Clinical trial protocols may be several hundred pages long and require a large time investment by highly qualified people to interpret fully.
In the legal industry, NLP software is commonplace for organizing, tracking, and performing advanced predictive analytics, clustering, and discovery on legal cases which are formed of bundles of documents. Examples of advanced legal NLP software include Luminance29 and Everlaw30, which facilitate the manual review of legal contracts, leases, messages, depositions, interview transcripts, and other documents. We are not aware of a counterpart to these toolkits in the pharmaceutical industry, although there has been research and development on applications of NLP in the field31–33.
In 2020, Richard et al. published a comparison of NLP techniques for use on clinical trial protocol deviations, focusing on term-frequency inverse-document-frequency (Tf*Idf), support vector machines (SVM), and word vector embeddings34. In the same year, Chen et al. performed a topic modeling analysis of the literature on NLP techniques in clinical trial texts, identifying key trends in NLP-enhanced clinical trial processing and research35.
The Bill & Melinda Gates Foundation created a group called DAC (Design, Analyze, Communicate) which is intended to optimize the informativeness of research and includes resources on best practices to reduce the risk of trials ending uninformatively. An investigator choosing to work with DAC can submit their protocol draft, and receive a list of recommendations on 16 best practices for informativeness4.
In 2018, David Fogel described a number of common causes of trial failure, such as underpowering, safety issues, and lack of funding. Fogel proposed several opportunities for applying artificial intelligence, in particular NLP, to identify these factors. He suggested using NLP to mine available literature and previous trials in order to determine if a trial is using appropriate endpoints, eligibility criteria, and sample sizes, and to check for internal inconsistencies in a protocol36. Fogel also suggested using other areas of AI and machine learning to profile patients to reduce the probability of attrition, modeling patient drop-out rates with neural networks.
In 2023, Chang et al. used a contrast mining framework to identify the key indicators of successful and unsuccessful cancer trials, and used NLP to extract eligibility criteria from protocol documents, among other techniques37.
We are unaware of any existing automated tool using only NLP to extract risk factors from trial protocols.
Although protocols are written in technical English, they are not constrained by any particular standard. Protocols from within a given organization generally follow a rough pattern, but there are many ways that a particular data point can be communicated: the sample size could be referred to as the “number of participants,” or “N = 90,” or the researchers could write simply “we plan to enroll up to 100 subjects per site,” and leave it to the reader to infer the sample size.
The result is that a person reading a protocol, who simply wants to find the sample size, effect size, prevalence, or other figure, must search the entire text for a number of possible keywords, refer to the contents page, or even worse, begin reading the entire paper from start to finish. This is a time consuming and error-prone process, and far from the best use of a professional’s time.
In this paper, we present a software tool called the Clinical Trial Risk Tool38, which parses the PDF of a trial protocol and identifies key features within the text, such as the number of participants (the sample size), or the presence or absence of the Statistical Analysis Plan. The Clinical Trial Risk Tool then passes these features into a simple linear risk model and calculates a risk level, which is presented to the user as a traffic-light, indicating a high, medium, or low risk of ending uninformatively. The features of the risk model can be adjusted manually and saved by the user. The tool generates a PDF or Excel report which can be shared within the organization. The tool has been designed and trained with a focus on HIV and Tuberculosis (TB) trials but could be adapted to more pathologies.
The tool has been open-sourced under MIT License and deployed to the internet at the following link: https://app.clinicaltrialrisk.org.
The Clinical Trial Risk Tool is a web application written in Python39, using the graphical interface library Plotly Dash40, and the machine learning libraries NLTK41, spaCy42, and Scikit-Learn43. The tool was developed as a Docker container44 and can run on any browser.
The tool is architected as a Python server which contains most of the logic, which connects to a Java-based server running Tika for PDF parsing (Figure 1).
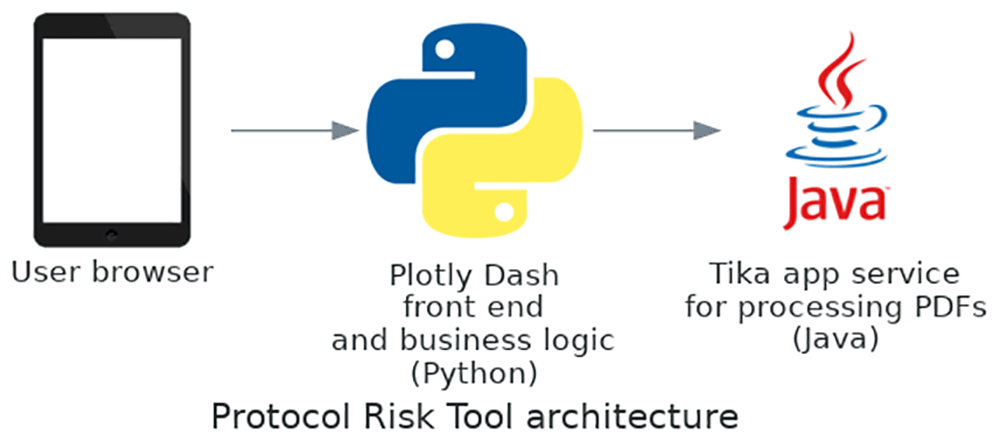
This server also connects to a separate server running Java and Tika for PDF parsing.
Users have the option to login and create and save profiles.
The tool allows a user to upload a trial protocol in PDF format. The tool processes the PDF into plain text using the software Apache Tika45, and identifies features in the document content which indicate high or low risk of uninformativeness.
The tool extracts eight features. The features are:
1. Pathology (limited to HIV and TB at this stage)
2. Trial phase
3. Is a Statistical Analysis Plan (SAP) present?
4. Is the effect estimate disclosed?
5. Number of subjects (sample size)
6. Number of arms
7. Countries of investigation
8. Does the trial use simulation for sample size determination?
The features are then passed into a scoring formula which scores the protocol from 0 to 100, and then the protocol is flagged as HIGH, MEDIUM or LOW risk.
The tool allows for risk profiles and thresholds to be saved and loaded if the user is logged in (Figure 2).
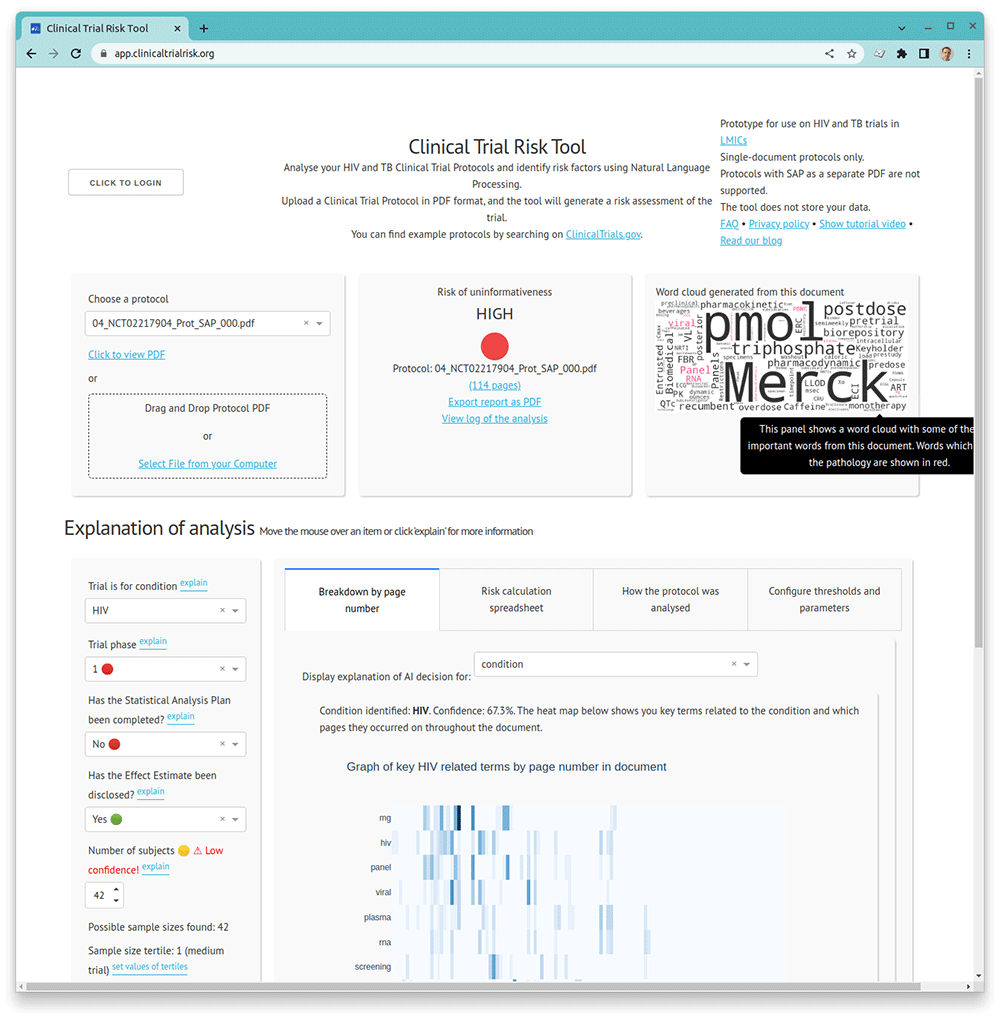
Before beginning development of the AI models, it was necessary to first identify the features which it would be advantageous for a tool to extract. It would be futile to spend a lot of time developing a model to extract a particular feature, only to discover that it has no or very little influence on the overall risk rating of a trial.
We conducted a survey of two subject matter experts within the Bill & Melinda Gates Foundation (BMGF) to gather information on which features would be helpful to focus on, independently of the technical difficulty of extracting that feature from the protocol text using NLP. Participants were sent a link to a questionnaire using the cloud-based software SurveyMonkey46, which asked them to rank features of a protocol text in order of their level of influence on the protocol’s success or failure in terms of informativeness (original questionnaire available here). A screenshot of the survey interface is given in Figure 8. The consensus was that the SAP is by far the most informative feature, so it was decided to focus initially on developing an NLP model to identify the presence or absence of an SAP. This survey, although qualitative, may be useful in future if the tool is developed further.
We took inspiration from the table of indicators of risk of uninformativeness given in Zarin et al.6.
The results of our survey, ranked in descending order of importance, are given in Table 1.
Two datasets were used to train and validate the tool.
Manual dataset. A set of 300 protocols, some supplied by the BMGF and some downloaded from ClinicalTrials.gov, were read through individually and annotated with key features: the sample size, pathology, number of arms, phase, intervention type, countries of investigation, presence of SAP, effect estimate, use of simulation. The number of protocols manually annotated per parameter varied between 100 and 300.
ClinicalTrials.gov dataset. The ClinicalTrials.gov dataset was a much larger dataset of 11,925 protocols which was downloaded from the ClinicalTrials.gov AACT data dump on 4 Nov 202247. The data dump came in the form of a PostgreSQL database48 and included the protocol PDFs and metadata on the National Clinical Trial (NCT) ID, phase, pathology, presence or absence of an SAP, number of arms and number of subjects. However, these values were voluntarily provided by the researchers and in many cases are out of date or inaccurate.
By combining the two datasets, it was possible to combine some of the advantages of a large dataset with some of the advantages of a smaller, more accurate dataset.
Each parameter is identified in the document by a stand-alone component using machine learning and, optionally, some manually coded rules. The machine learning techniques used were naive Bayes classifiers, random forest classifiers, and convolutional neural networks. Examples of manual rules are “a number followed by a unit such as ‘mmHg’ cannot be a sample size”. In particular, country names were identified using a dictionary lookup approach with some exceptions, such as “a mention of ‘Georgia’ is most likely to be the US state unless other words occur in the vicinity which indicate Georgia the country”.
The output values from these components are then fed into the linear risk model, which calculates the overall risk score of the protocol.
An additional Naïve Bayes classifier was used to obtain a baseline performance on each parameter before more advanced models were trained.
Pathology (condition). The pathology of a trial is identified using a three-way Naïve Bayes classifier operating on the text of the whole document on token level, which classifies documents into HIV, TB, or Other. It treats HIV and TB as mutually exclusive, although in future work more pathologies could be covered and the tool could assign a document to multiple pathologies.
To develop this, protocols were manually tagged as HIV, TB or other and the tool learnt which words are indicative of which pathology.
The classifier was trained on the manual dataset as a three-class classifier, but could easily be extended in future to cover more pathologies.
The tool also identifies key words and phrases throughout the document which are related to pathology and presents these to the user.
Trial phase. Trial phase is represented in the model by a floating-point number (whole number or whole number plus 0.5) between 0 and 4, where 1.5 means Phase I/II. The model for extracting the phase was implemented as an ensemble between a convolutional neural network text classifier, implemented using the NLP library spaCy, and a rule-based pattern matching algorithm combined with a rule-based feature extraction stage and a random forest binary classifier, implemented using Scikit-Learn (RRID:SCR_002577). Both models in the ensemble output an array of probabilities, which were averaged to produce a final array. The phase candidate returned by the ensemble model was the maximum likelihood value.
Presence or absence of statistical analysis plan (SAP). The presence or absence of an SAP is identified via a Naïve Bayes classifier operating on the text of the whole document on word level. In addition, candidate pages which are likely to be part of the SAP are highlighted to the user using a Naïve Bayes classifier operating on the text of each page individually.
Effect estimate. A rule-based component written in spaCy identifies candidate values for the effect estimate from the numeric substrings present in the document. These can be presented as percentages, fractions, or take other surface forms. A weighted Naïve Bayes classifier which is applied to a window of 20 tokens around each candidate number found in the document, and the highest ranking effect estimate candidates are returned. The values are displayed to the user, but only the binary value of the presence or absence of an effect estimate enters into the risk calculation.
Number of subjects (sample size). A rule-based component written in spaCy identifies candidate values for the sample size from the numeric substrings present in the document. These values are then passed to a random forest classifier, which ranks them by likelihood of being the true sample size, and identifies any substrings such as “per arm” or “per cohort”, which can then be used to multiply by the number of arms if applicable.
Number of arms. The number of arms is identified using an ensemble machine learning and rule-based tool using the NLP library spaCy and scikit-learn Random Forest.
Countries of investigation. The countries of investigation are identified using an ensemble of machine learning and rule based components using regular expressions and Keras convolutional neural networks, which are combined using a Scikit-Learn Random Forest model.
Simulation used for sample size determination. This is a Naïve Bayes classifier operating on the text of each page individually. If a page contains information about simulation being used for sample size, the classifier classifies that page as 1, otherwise as 0. If any page in the whole document is classified as class 1, then the protocol is considered to have used simulation for sample size determination.
Although trials may use simulation at various points, the data tagged for simulation includes only trials using simulation specifically for sample size planning. Trials using simulation for later stages of statistical analysis are excluded.
Sample size tertiles. The sample size is not fed directly into the risk model, but is converted into a value of 0, 1, or 2, representing the tertile of that sample size within a dataset of comparable trials (same phase and pathology).
The default sample size tertile threshold values are given in Table 2, but the user can change these values.
| Phase | HIV lower tertile | HIV upper tertile | TB lower tertile | TB upper tertile |
|---|---|---|---|---|
| 0 | 10 | 15 | 10 | 15 |
| 0.5 | 40 | 130 | 30 | 60 |
| 1 | 40 | 130 | 30 | 60 |
| 1.5 | 80 | 280 | 40 | 80 |
| 2 | 100 | 300 | 50 | 100 |
| 2.5 | 1000 | 2000 | 500 | 1500 |
| 3 | 1000 | 2000 | 500 | 1500 |
| 4 | 3000 | 4000 | 3000 | 4000 |
The default sample size tertiles were derived from a sample of 21 trials in LMICs, but have been rounded and manually adjusted based on statistics from ClinicalTrials.gov data.
The tertiles were first calculated using the training dataset, but in a number of phase and pathology combinations the data was too sparse and so tertile values had to be used from ClinicalTrials.gov. The ClinicalTrials.gov data dump was used from 28 Feb 2022.
Linear risk model. The features extracted by the NLP components are fed into a linear scoring formula, which was designed for this software.
Each parameter is converted into an integer or floating-point number, and multiplied by an associated weight, and this is used to calculate a score between 0 and 100. From this score, the protocol is flagged as HIGH, MEDIUM or LOW risk. For example, a protocol scores 26 points for having a completed SAP, and a protocol scoring above 50 points in total for all features is considered low risk. The linear formula has a bias term of -7.
Protocols scoring 50 or above are considered by default to be low risk. Protocols which score 40 or above but below 50 are marked as medium risk, and scores below 40 are high risk.
Our formula can be summarized as follows:
Where the xi are the features extracted from the text. All features are binary variables except for sample size tertile (0 = small trial, 1 = medium trial, 2 = large trial), phase, and number of arms (which is capped at 5 to avoid distortions caused by any trials with an unusually large number of arms).
Our formula can be seen as a form of linear regression, where the weights were arrived at via human reasoning rather than a loss function.
The risk values were arrived at as part of a qualitative process in consultation with subject matter experts, who identified the features that they would look for in assessing a protocol for risk manually. The consensus was that the SAP is by far the strongest predictor of risk (a trial lacking an SAP is extremely unlikely to succeed).
The default feature weights are given in Table 3.
The Clinical Trial Risk Tool can be accessed via any web browser here. All computations are conducted remotely on a Python server. The software has an embedded video tutorial to ease the learning process. The user interface contains mouseover tooltips with layperson-friendly explanations of the options in the tool.
The user can adjust the sample size tertile thresholds and weights associated with the features in the user interface and save this as a configuration file.
A user has the option to click on the Login button to create a user account and save their configuration on the server. Authentication is managed by the third party authentication provider Auth0.com.
If a user wishes to use the application anonymously, all functionality is still available without logging in, but the user is not able to save and retrieve profiles at a later date.
A user uploads a PDF file of a clinical trial protocol, either by dragging and dropping it into the tool, or by using a file selector dialog. On the server side, the tool parses the raw PDF file into plain text, and then presents the user with the features that were identified in the text: pathology, phase, SAP, effect estimate, sample size, sample size tertile, number of arms, countries of investigation, and simulation.
The user can then correct these features by clicking on dropdowns and selecting or typing the correct value in the GUI.
In real-time, the features are fed into the risk model which presents the protocol’s risk level as a color-coded HIGH, MEDIUM or LOW risk.
The GUI includes a graph view of the key terms’ locations within the document by page number, allowing the user to quickly identify pages which are heavy in statistical content or other relevant terms. The tool’s analysis of the protocol of an HIV trial in 49 is shown in Figure 3.
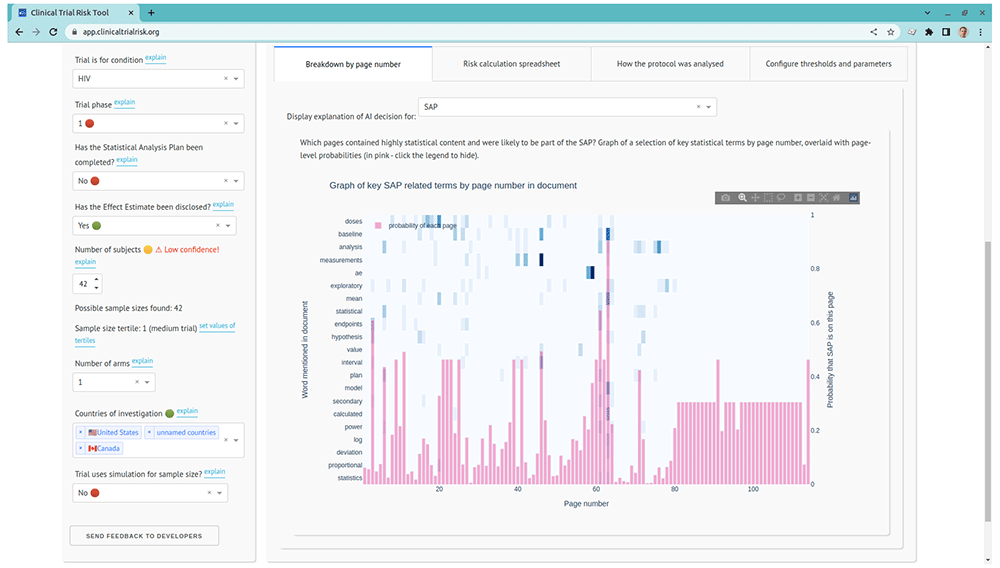
The user can export the risk assessment with all explanations and key figures to an Excel or PDF file.
Finally, if the user has changed the sample size tertile thresholds or feature weights, this configuration can be saved on the server (if the user is authenticated), or to the user’s local machine.
The tool was tested by internal and external subject matter experts, who provided feedback throughout the project. In this way, inaccuracies and pain points could be identified and fixed in an iterative process.
For validation on the manual dataset, cross-validation was used. For validation on the ClinicalTrials.gov dataset, Trials with values 0–7 as the third digit of their numeric NCT ID were used for training, with value 8 were used for validation, and those with value 9 are held out as a future test set.
The validation scores on small manually labeled dataset (about 100 protocols labeled, but 300 labeled for number of subjects) are given in Table 4.
Each component was validated using accuracy and Area Under the Curve (AUC).
Accuracy figures are reported in Table 5 together with performance of a comparable Naïve Bayes baseline model trained on the ClinicalTrials.gov training dataset, which can provide an estimate of a reasonable baseline performance.
In addition to validating the performance of the NLP components of the tool, it was also necessary to validate the risk model.
We took the dataset of 125 trials analyzed by Hutchinson et al. in their 2022 analysis, where they attempted to establish the proportion of RCTs that inform clinical practice3. Unfortunately, only six of the protocols in that study could be located from ClinicalTrials.gov.
We passed these six protocols through the tool and compared the risk output of the tool to whether or not Hutchinson et al. considered the trials informative (Table 6). On this small dataset, the tool predicted informativeness with 100% AUC (the two trials scoring 60 or below were not informative). This was a useful sanity check for the risk model, although the test set is far too small for this test to be scientifically rigorous.
We have validated the individual components of the tool separately. Accuracies vary among the datasets and components validated.
In particular, the sample size component’s accuracy on the ClinicalTrials.gov dataset was particularly inaccurate. The low performance for that value is due to lack of a reliable gold standard, rather than low performance of the risk tool itself. The sample size identification was particularly challenging and required the manual labeling of 300 protocols in order to achieve a performance that was acceptable in user testing. This is because the sample size cannot be reduced to a simple three- or four-way classification problem like many of the other features, but is a problem of data extraction with many confounding factors such as false positives.
It is fortunate that some of the most important features, such as the presence or absence of the SAP, were relatively easy to identify with machine learning (since SAP can be reduced to a binary classification problem, which is one of the easiest kinds of problems to solve in machine learning).
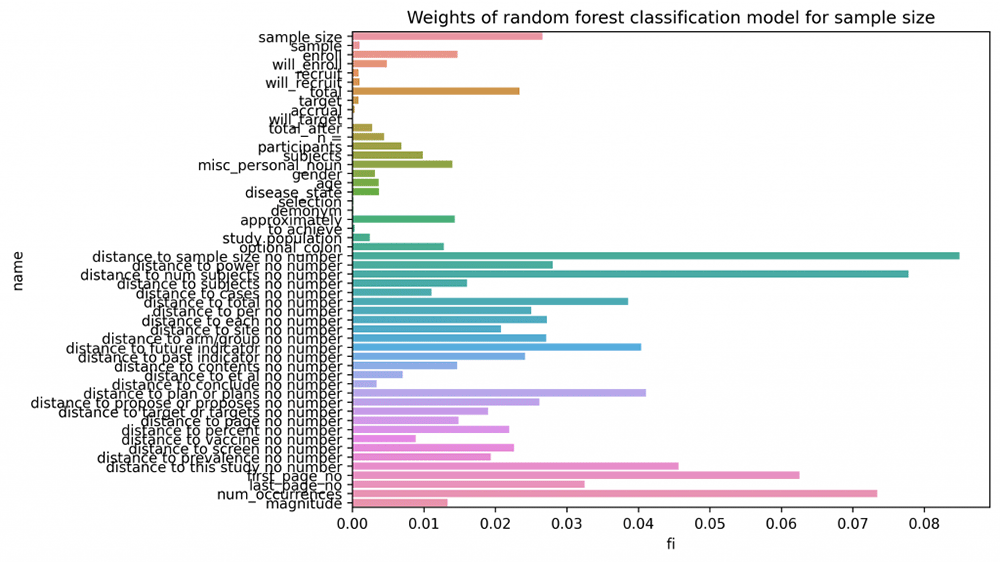
We were able to look inside the parameters of the models that are used to extract the individual features, in order to search for any potential improvements. For example, the sample size extraction component identifies candidate sample sizes in the text using a set of manually created rules, and calculates features for each of them (distance in tokens to the term “sample size”, etc). The Random Forest model allows us to visualize the feature importances of the model, and we see at a glance that the strongest indicators that a number in the text is the true sample size are the distance to the terms “sample size” and “number of subjects”, followed by the num_occurrences (the number of times that number occurs in the text). The feature importances of the sample size classifier are shown in Figure 4.
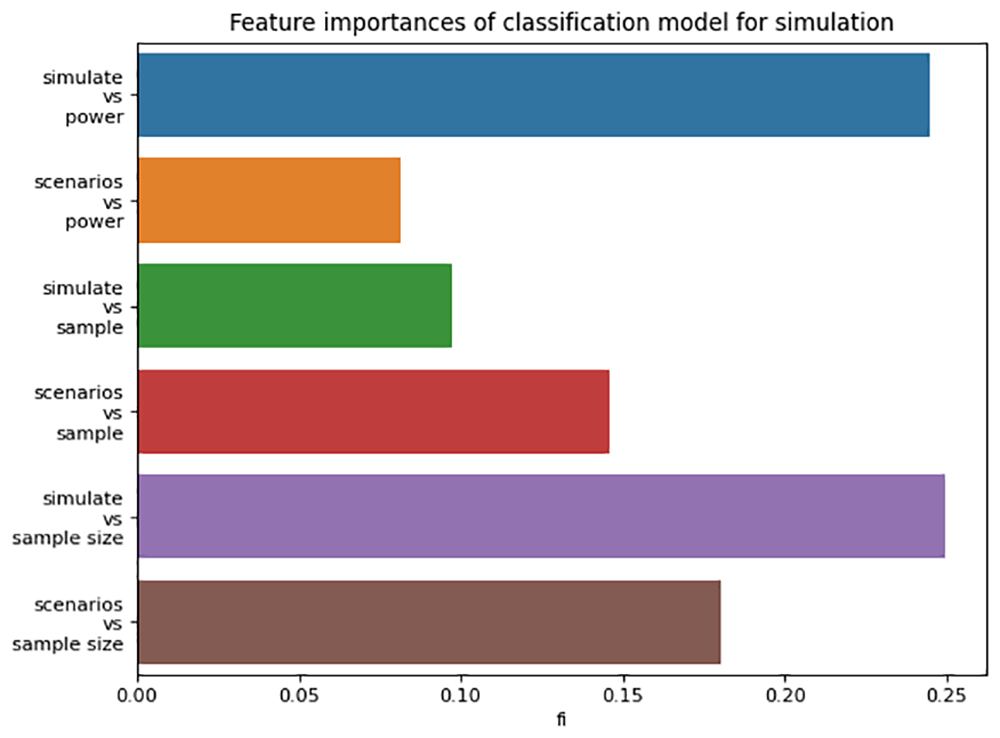
Likewise, the feature importances for the component that extracts mentions of “simulation” are shown in Figure 5.
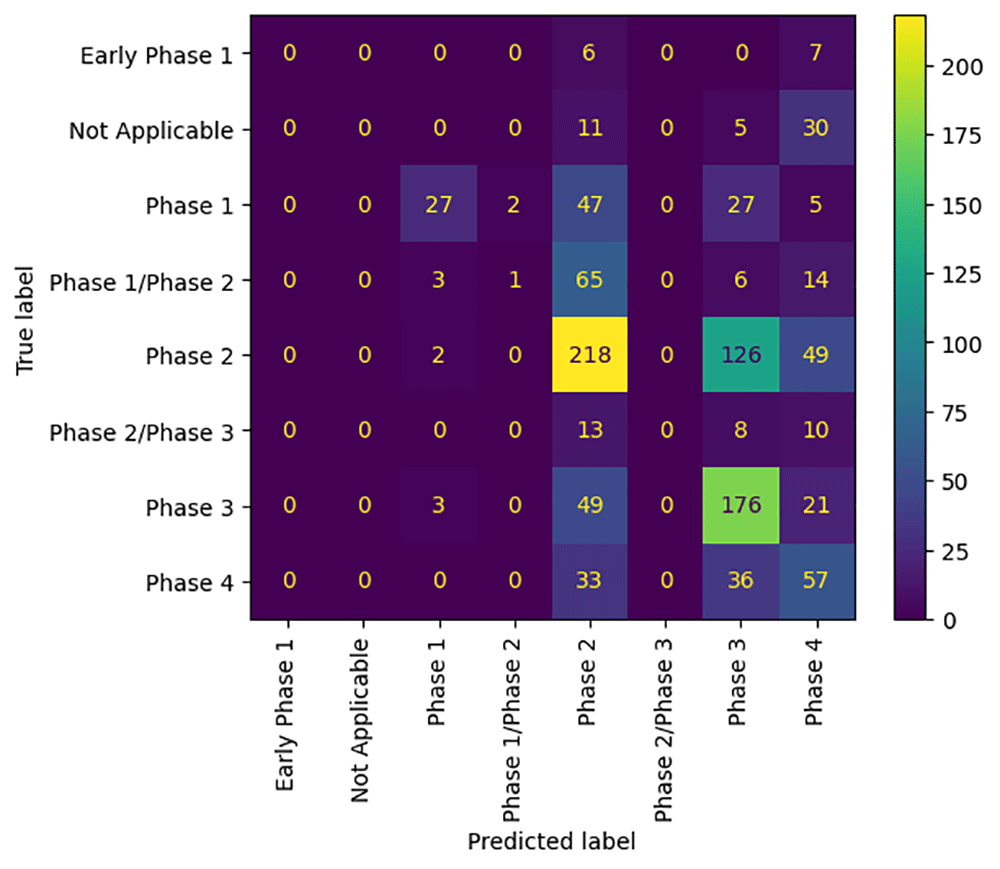
We have also explored the performance of the models using more sophisticated metrics than AUC and accuracy. For example, Figure 6 shows the confusion matrix of the phase extractor. We can see at a glance that the commonest phases in the dataset are 2 and 3, and phase 2 is likely to be confused with phase 1.5 (I/II).
The confusion matrix visualization also makes it clear how much harder the sample size identification is compared to the other features that the tool extracts from the protocol text. Figure 7 shows the confusion matrix for the sample size detection component.
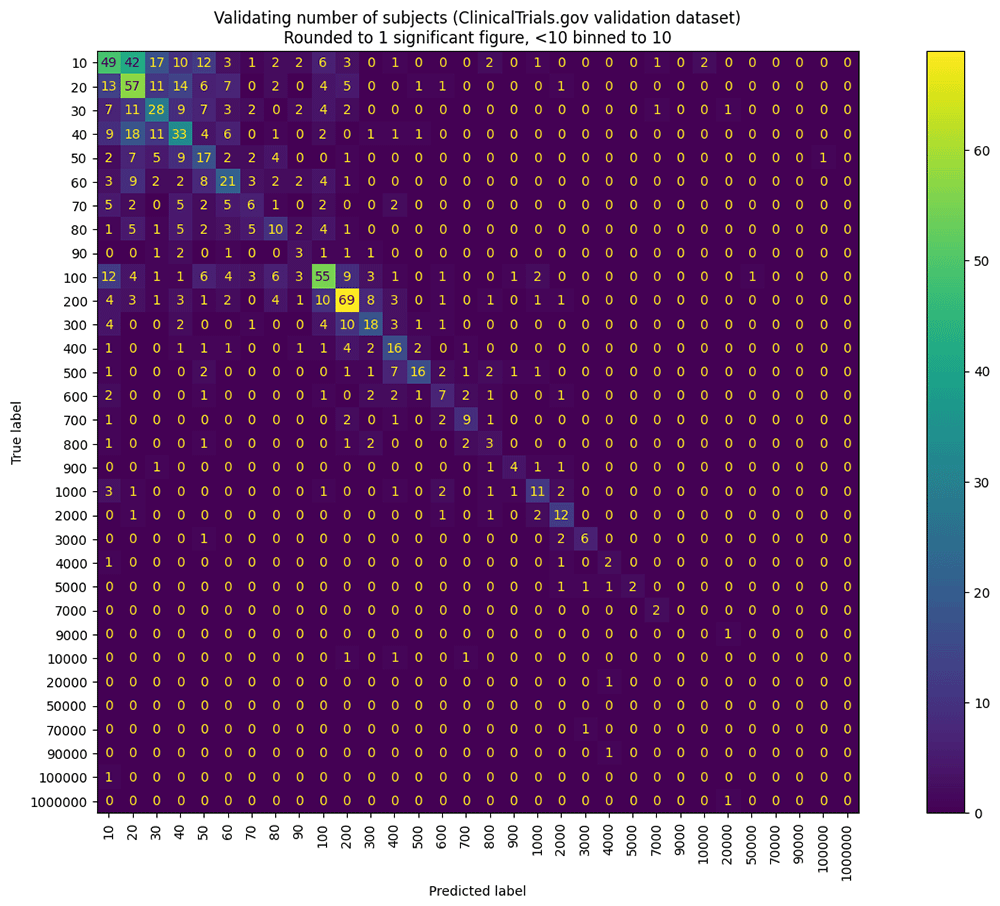

In our accuracy calculations, we have considered a sample size to be correct only when it is exactly equal to the true value, so a predicted value of 61 for a ground truth of 62 would be considered an error. For the purposes of the confusion matrix, we allowed a tolerance of 1 significant figure. We can see at a glance that low sample sizes (10–30) are the ones most likely to be confused by the model.
We have provided Jupyter notebooks in the repository to run the validation and reproduce the results.
It was not possible to conduct a thorough analysis of the linear risk model due to data on “informativeness” of clinical trials being harder to obtain, and the intersection of that data with the available trial protocol documents being small. Further studies are needed to validate the risk modeling part of the tool.
A funding organization receives large volumes of incoming protocols. They have a team of reviewers who are reading the documents and categorizing them as ‘go’ or ‘no-go’. The majority of protocols are not accepted for funding, because they do not meet some of the funder’s criteria. The organization would prefer to spend less time on the high-risk protocols.
Using the Clinical Trial Risk Tool, the reviewers would be able to quickly identify the incoming protocols which should not be considered for funding, such as those which are missing key statistical information. This frees up more of their time to process the high-quality protocols.
When protocols are passed to reviewers, each reviewer typically comes from a different background and brings with them their own way of viewing a protocol. The reviewing team could use the tool to calibrate and standardize their review processes for greater consistency. For example, they could agree on a standard set of weights and parameters for the model and save it on an organizational or departmental level.
An investigator is preparing a trial protocol for submission as part of a funding application. Each funding organization has their own checklist of key ‘must-haves’ and ‘should-haves’ in a trial. The applicant uses the Clinical Trial Risk tool to vet their protocol and identify any weak points. For example, the tool may flag the trial as high risk because the expected effect estimate is not clearly stated. This gives the investigator an opportunity to correct the issue before submission, increasing the chances of acceptance.
The tool can be used for education and training of investigators or reviewers on what makes a robust protocol, facilitating the upskilling of junior reviewers.
Some funding organizations, such as the Bill & Melinda Gates Foundation, require a risk assessment questionnaire (the DAC risk assessment questionnaire) to be submitted together with the protocol. If the tool is exposed as an application programmable interface (API), it can be used for auto-population of the risk assessment questionnaire. This streamlines the submission process, as the tool can retrieve important information from the PDF in seconds, freeing the applicant to do other tasks.
A pharmaceutical company may like to use the tool to estimate the cost of an oncology trial. The tool source code is open source, so the pharmaceutical company can engage a developer to modify the tool to estimate a dollar value of the trial. New features have to be added, such as cancer stage, and number of chemotherapy cycles, but fortunately the developer can ‘recycle’ the code that is currently identifying trial phase for these purposes. The company has a database of past trials and confidential and sensitive industry data on their cost over the last ten years, which are used to train a regression model to predict the cost. The tool’s performance can be validated on data on the most recent trials if that has been withheld from the training data. The pharmaceutical company now has a customized in-house cost estimation tool. Since the Clinical Trial Risk Tool is under MIT License, this means that the pharma company is not obligated to share its in-house cost model, which contains industry-sensitive data, but they choose to put the oncology-specific NLP features that they have added to the tool in the public domain.
We have developed a software tool which we believe is unique in using natural language processing to provide a risk profile of a clinical trial protocol.
The tool can assist a human in assessing the risk of uninformativeness of a trial, and understanding which factors contribute to the risk of uninformativeness. With the use of this tool, reviewers may be able to assess trials more rapidly, and the tool could be used to inform stakeholders about the most impactful features for risk of uninformativeness. The tool can also assist reviewers in assessing trials more consistently, and investigators may use it to validate their draft protocols before submitting them to a funding organization.
The use of the tool is intuitive and the software is open-source and can be accessed via any web browser, allowing clinical trial investigators who do not have the expertise in software or programming to use the tool.
Since the software is open source under an MIT License, an investigator can easily fork the project and extend it to another field such as oncology, or to predict trial cost or complexity, with relatively little effort.
Validation of the tool has been complex because each component of the tool has been designed independently, and the data on ClinicalTrials.gov is not entirely accurate because it depends on researchers updating their profiles manually. It was time consuming to manually annotate large numbers of protocols, but further manual labeling could pave the way for further improvements in accuracy. There is still much scope for improvement of several features, especially sample size.
The tool is trained to detect only two pathologies, HIV and TB. However, if a user uploads a protocol from a different pathology, they could still use the tool for risk assessment, but they would need to set appropriate values for the feature weights and sample size tertiles. For some high-risk pathologies, such as oncology or cardiovascular disease, we would not expect the tool to be as accurate at identifying risk, because of the importance of other features, such as biomarkers, enrolment criteria, toxicity of treatment, and chemotherapy cycles, which are not currently handled in the tool, but which are important for these pathologies7.
Future work on this project could involve broadening the scope to more pathologies, or altering the tool to predict cost, complexity or other key metrics of a trial. If we were to extract further features from the text using NLP, candidate features would include the number of endpoints, the prevalence estimate not being disclosed, the trial being a platform trial, the protocol being a master protocol, and more.
User requested features include support for multi-document protocols (e.g. Protocol and SAP in separate PDFs), or support for processing of multiple documents at the same time, or exposing the tool as an API or library.
One potential future extension of the project would see the tool developed further into a case management system, which would ingest protocols, SAPs, questionnaires, and regulatory paperwork, and track the associated metadata on trial level, similar to the legal case management systems described in the Introduction.
No ethical approval was sought for this study due to the very low risk nature of the survey conducted, where no personal or identifiable information was collected.
Completion of this survey implied consent for data collection, with written informed consent obtained from each participant before the publication of this manuscript for publication and use of their data
SAP: Statistical Analysis Plan
NLP: Natural Language Processing
HIV: Human Immunodeficiency Virus
TB: Tuberculosis
CNN: Convolutional Neural Network
NLTK: Natural Language Toolkit
Tf*Idf: term frequency*inverse document frequency
AI: Artificial Intelligence
GUI: Graphical User Interface
AUC: Area Under the [ROC] Curve
ROC: Receiver Operating Characteristic
PDF: Portable Document Format
API: Application Programmable Interface
RCT: Randomized Clinical Trial
| Views | Downloads | |
|---|---|---|
| Gates Open Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with Gates Open Research
Already registered? Sign in
If you are a previous or current Gates grant holder, sign up for information about developments, publishing and publications from Gates Open Research.
We'll keep you updated on any major new updates to Gates Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)