Keywords
ear identification, patient identification, growth curves, biometrics, global health
ear identification, patient identification, growth curves, biometrics, global health
The coordinated delivery of healthcare services relies heavily on accurately and repeatedly identifying each individual at the point of care. Everything from effective disease management to tracking vaccination records hinges on reliable patient identification.
In the USA, the expanded adoption of electronic health records (EHRs) was largely driven by the HITECH Act passed in 2009, increasing adoption rates from 3.2% to 86% in 20171. EHRs were rolled out with promises to improve quality and efficiency of care. While the shift from paper-based record systems to EHRs has promised to improve the delivery, management, and coordination of care, they carry little to no advantage over their paper-based counterparts unless the subject identification problem has been solved. Without that solution, EHRs quickly become overloaded with duplicate and incomplete patient records resulting in many of the same inefficiencies as a paper-based system. An audit of Children’s Medical Center in Texas found that duplicate records led not only to administrative costs incurred by the hospital to merge and/or store the records in a database, but also to unnecessary medical care costs incurred by the patient2.
In low- and middle-income countries, like Zambia, the advantages of transitioning from paper-based systems to EHRs have been promoted as a mechanism to improve the quality of care and to provide data by which to monitor and evaluate programs. Unfortunately, the challenge of subject identification has proven a significant barrier to realizing these benefits. In 2004, the Zambian Ministry of Health and the US Centers for Disease Control rolled out SmartCare, a Windows-based clinical information management system. SmartCare was originally intended to support HIV care delivery services but has since expanded to include other non-HIV care services.
Upon enrollment into SmartCare, each patient is given a “Care Card”. The Care Card acts as the patient’s unique identifier. Healthcare workers scan this card to access the patient’s digital health records. If a patient is unable to produce her/his card at a clinical encounter, the healthcare worker must rely on other external identifiers (a database search involving names, dates of birth). Often, a patient without a Care Card is not successfully found in the system, and a duplicate record is created that does not contain the patient’s longitudinal medical history. The inability to link a patient to their correct medical record leads to costly inefficiencies, the proliferation of aliases, and ultimately gaps in care delivery3. Given the difficulties of developing a robust identification system based on ID cards or other external identifiers, there is considerable interest in using biometrics to identify an individual in healthcare settings4,5.
For the last several years, our team has focused on solving the patient identification challenge through ear biometrics. Through our NIH-funded research, Project SEARCH (Scanning Ears for Child Health) we were able to develop a mHealth tool that was an accurate and acceptable way of identifying a cohort of Zambian infants. The current SEARCH system takes an image of an individual’s ear and displays a list of top-ten likely matches. From this list, the user can leverage other demographics linked to the individual to select the correct match. The system consists of a hardware component, the “Donut” to optimize the image-capture process, and a mobile application that uses a pattern recognition algorithm, Scale Invariant Feature Transformation (SIFT), to transform an image of the ear into a unique identifier6. In previous experiments using three distinct cross-sectional cohorts of increasing complexity, top-1 matching rates (when the correct individual appeared first on the list of top-10 matches) of the SEARCH system reached 100%7–9.
Previous experiments, however, did not account for the impact of ear growth on identification, a problem that may be particularly challenging early in infancy when growth velocities are maximal. An essential first step in our analysis is to characterize the normal trajectory of ear growth during the first 9 months of life, to assess how balanced this is between the right and left ears, and whether there are substantial differences in growth based on sex. From that baseline, our analysis focused on 1) understanding the impact of growth on ear biometric matching rates; and 2) assessing the ability of the computer science technique of concatenation to counter the negative effects of growth on matching accuracy.
This section describes the creation of the longitudinal dataset, methods for measuring ear growth, the image matching pathway (how a match is made using ear biometrics) and optimizations made to the matching pathway.
Data were collected at the Chawama Clinic among infants attending routine well-child care visits. The Chawama township is one of the largest, most densely populated, and poorest section of Lusaka.
Written consent forms were approved to collect non-medically sensitive data from participants in this study. All forms were translated into two local languages and approved by both the Boston University IRB and University of Zambia Board of Ethics. Approval/Reference Number: H-38650. To be included in the study, all participants had to be attending Chawama Clinic for a vaccination visit and planning to attend well-child visits at Chawama Clinic in the future. Infants with a low birthweight (<2.5 kg) were excluded from the study.
Data collection spanned a period of 6 months from 11/2019 through 04/2020.
We enrolled 227 infants attending Chawama Clinic. The infants were either enrolled at their regular day 6 post-partum well-child follow up visit (creating the cohort providing growth data between just after birth and 14 weeks of age), or were older infants enrolled at their regular 14-week well-child visit (creating the cohort that provided growth data from 14 week through 9 months). By enrolling these two groups in parallel, we were able to shorten enrollment times and reduce study attrition over time. From 227 enrolled infants, we had 661 follow-up visits, the following age-specific datasets were acquired: 6 days (n=132); 6 weeks (n=109); 10 weeks (n=107); 14 weeks (n=150); 4 months (n=110); 5 months (n=54); 6 months (n=83); 7 months (n=89); 8 months (n=35); and 9 months (n=15). Loss to follow-up was highest in follow-up visits that did not coincide with vaccination (all visits past 14 weeks), and when data collection activities were temporarily halted due to CV19 pandemic in March 2020 (5 months and 9 months).
Data collection. The SEARCH system has two components, one hardware and one software. The hardware component is a light opaque cylinder, which we call the ‘Donut’. It is open on one end but mounts a semi lunar plastic insert shroud. The ear is cupped by the shroud, and the purpose of the shroud is to exclude distracting visual data from the image, such as the neck and hair. The other end mounts a flat plastic plate with a Velcro strip to mount the smart phone, with a hole through which the camera is directed.
In this project, we used an infant sized scaled-down version of the Donut, termed the ‘Munchkin’. The purpose of the Donut (and Munchkin) is essentially to minimize variation in the ear image capture process. The device accomplishes this by: (1) standardizing distance and angle from the camera to the ear, and thereby maintaining a constant camera focus length; (2) minimizing variations in light intensity for the photo both by having the device supply its own lighting through a ring of 360 degree LED lights built with a voltage regulator; and because the donut cylinder is light opaque, such that the only light seen by the camera would come from the donut itself; and (3) by reducing motion artifact since the donut, when applied to the side of the head, stabilizes the camera. Prior work has shown that the Donut significantly improves the accuracy of the SEARCH system8.
Images were taken by one data collector, who was thoroughly trained and replaced the 9 Volt battery for the LED lights on a bi-weekly basis.
At enrollment we collected basic demographic data on each participant: age and sex. At baseline and all follow up visits, we obtained two images of the left ear and two images of the right ear, plus their current weight. In this way, we created a longitudinal library of ear images with paired infant growth data, allowing us to observe the relationship between ear growth over time and weight gain over time.
In early proof of concept experiments, a methodology was created to systematically measure radial measurements of the ear based on key anatomical features10. We adapted this methodology for the purpose of measuring ear area and radial measurements. The ear is a complicated anatomical structure, with features that vary from individual to individual. One exception is the point where two cartilage structures meet and form a point that is present across most ears that were observed. We’ve named this the ‘anchor point’, and this is the point from which we derived all subsequent growth annotations (see Figure 5).
Annotations: manual measurements. Manual measurements were taken on a subset of 90 participants. These measurements included 13 radial measurements and a polygonal area measurement (per ear image) that were taken using a MATLAB-aided user-interface. To set up for the radial measurements in a systematic way, the user first defined the base line which runs through the anchor point, tangent to the tragus. The first measurement C1, runs from the anchor point to where the baseline intersects with the ear. Following C1, each radial measurement starts from the anchor point and is offset by 15 degrees from the previous radial measurement (Figure 5(i)). A polygon was automatically generated using the endpoints of all radial measurements and the baseline. Because each image was taken at a fixed distance using the Donut, the ear area was defined as the area of the polygon and was calculated using a pixel to millimeter conversion based on known dimensions of the Donut.
Annotations: automated area measurements. A subset of 35 manual area measurements were saved as masked data in Matlab R2020b (RRID:SCR_001622) (.mat files containing the location of the polygonal region of interest or area). Alternatively, this could be done by writing a similar program in Google Colaboratory. We trained a Faster R-CNN12 detection network to detect the ear area from the taken photo. We trained it with 165 manually labeled images in our collected ear data. We adopt the trained Faster R-CNN network to detect the ear area of the rest of the ear images in our collected data. The full dataset of n=227 participants (left and right ears for each visit) was the input into the trained model. The output was area measurements and masked ear images for all 227 participant datasets (Figure 5(ii)).
We performed a regression using the larger subset of 90 participants. Here we compared automatic area measurements with the manual measurements from these participants (Figure 5(iii)). Since there was a strong correlation, we then transitioned to using automated area measurements for analysis.
Earlier work under Project SEARCH set out to prove that ears could be used as a biometric identifier. In doing so, a number of pattern recognition algorithms were tested on a dataset of ear images. The Scale Invariant Feature Transform (SIFT) algorithm stood out as the optimal candidate6. When provided with an image, the SIFT algorithm tries to detect local points of interest called “keypoints”. When all the keypoints in the image are detected, the set of keypoints describing the image are converted into a vector of values called a “descriptor”. The descriptor can then be compared against descriptors of other images, calculating the Euclidean distance between keypoints in each descriptor. The result of this is an average distance score for each set of descriptors being compared9,11. A low average distance score is indicative of a stronger match, so the descriptor that yielded the lowest score is returned as the matching image.
Implementation. For all experiments conducted, the application used was built on Android OS. The intention is to have an on-device matching solution deployable in low- and middle-income countries, and in doing so the cost and viability of the platform have to be considered. The SIFT implementation packaged in the OpenCV library was used9.
Operation. To run the application, Android OS 5.0 or higher is required. OpenCV version 2.4.11 is used.
Look-back Period Tests. In the look-back tests, we analyze recognition rates associated with images taken of participants at different points in time. The recognition rate of each test is defined as the percent of participants in the testing dataset (n) that successfully match to an image in the training dataset (database n) divided by the total possible correct matches. The calculation of this rate does not take into account the size of the database n.
Due to loss to follow-up along with a staggered enrollment at 6 days and 14 weeks (thus overlap in the two cohorts), the training and testing datasets for each test do not have equivalent sample sizes (defined as n and database n). Figure 6 uses a simplified example of a 7 month to 6 month look-back test to illustrate how recognition rates are determined for single look-back periods. All look-back tests follow this same approach. For experiment three, database n for the concatenated look-back tests contains data from participants who had images stored for both specified time periods.
Keypoint concatenation. As described in an earlier publication, this technique allows for two or more image descriptors to be combined prior to matching7,12. Matching with these complex descriptors allows the SIFT algorithm to identify more of the unique features in a participant’s ear images. The four images captured per participant allowed for a number of varying concatenation configurations to be tested, allowing us to test the performance of concatenating multiple images from the same ear against a concatenation technique that used images from both ears for example.
Growth curves were created using SAS JMP software v.16.0.0 (RRID:SCR_014242). Alternatively, Google Colaboratory could be used to run a similar analysis. For the cumulative growth charts (ear area versus age, and weight versus age), we smoothed the graph using a cubic spline bounded by 95% confidence intervals. We used matched paired t-tests to conduct the mean difference in ear area between visits analysis. These experiments were conducted for consecutive visits, with a critical p-value of 0.05 to determine significance (Figure 2, Table 3 in extended data). Finally, we used a linear regression bounded by 95% confidence intervals to plot ear area versus weight. We calculated R2 values for each configuration (left and right ear area by weight for males, left and right ear area by weight for females).
To study the impact of growth, we assembled a two-segment longitudinal cohort consisting of Zambian infants enrolled at 6 days and from 14 weeks of age, both followed for up to six months. By combining these two, we can map ear growth and matching rates from birth through 9 months of life. We refer to this as a “benchmarking” cohort. These longitudinal data allowed us also to assess the degree to which different computer science enhancements, principally concatenation, might improve matching accuracy rates.
From these infants we obtained serial images of their ears, creating a time-series data set that simultaneously mapped the sex-specific growth of ears over time, and provided a series of pair-wise look back intervals across different points in time. We also generated growth curves, analogous to pediatric growth charts that plot age versus weight over time, so that we could explore the relationship between age, weight, and ear area. These measurements allowed us to isolate the effect of cumulative growth over time as well as growth velocity across different time points. The distinction between cumulative growth and growth velocity is potentially important given prior observations that the ear growth curve is steepest early in life but flattens out in the first year eventually becoming asymptotic.
During the project, a cohort of Zambian infants (N=227) were followed longitudinally over a six-month period at the Chawama Clinic health center in Lusaka, Zambia. We enrolled a cohort of 132 infants (50% female) at their 6-day vaccination visit. We enrolled a second cohort of 95 infants (46% female) at their 14-week vaccination visit. We recorded a monthly follow-up visit on infants in each cohort for 6 months. Demographic features of the cohort are summarized in Table 1.
This table shows the number of participants per visit, average age, average weight, and average ear area at each visit (left/right), grouped by sex. * signifies a significant difference in mean values between male and females (p<0.05).
| Female | Male | ||||||
|---|---|---|---|---|---|---|---|
| N (%) | Mean | SE / (CI 95%) | N (%) | Mean | SE/ (CI 95%) | ||
| 6 Day | Ear Area (Right/Left) (mm^2) | 66 (50%) | 541/544* | 9.8/11.1 | 66 (50%) | 583/579* | 9.8/11.1 |
| Age (days) | 7 | .15 | 7 | .15 | |||
| Weight (kg) | 3.1 | .05 | 3.0 | .05 | |||
| 6 Week | Ear Area (Right/Left) | 57 (48%) | 651/654* | 12.5/11.9 | 52 (52%) | 712/695* | 13.0/12.5 |
| Age (days) | 42.6 | .52 | 42.3 | .54 | |||
| Weight (kg) | 4.8* | .10 | 5.1* | .11 | |||
| 10 Week | Ear Area (Right/Left) | 55 (51%) | 708/726* | 15.0/15.4 | 52 (49%) | 776/778* | 15.4/15.9 |
| Age (days) | 75 | .6 | 75 | .6 | |||
| Weight (kg) | 5.6* | .09 | 6.0* | .09 | |||
| 14 Week | Ear Area (Right/Left) | 72 (48%) | 744/759* | 13.6/13.0 | 78 (52%) | 828/826* | 13.0/12.4 |
| Age | 106 | .6 | 105 | .6 | |||
| Weight | 6.2* | .10 | 6.7* | .09 | |||
| 4 Month | Ear Area (Right/Left) | 52 (47%) | 786/790* | 18.1/18.0 | 58 (53%) | 877/868* | 17.1/17.1 |
| Age (days) | 131 | 1.2 | 130 | 1.2 | |||
| Weight (kg) | 6.7* | .12 | 7.1* | .12 | |||
| 5 Month | Ear Area (Right/Left) | 21 (39%) | 763/786* | 25.2/23.6 | 33 (65%) | 890/900* | 20.1/18.8 |
| Age (days) | 152 | 1.7 | 149 | 1.4 | |||
| Weight (kg) | 6.6* | .17 | 7.1* | .14 | |||
| 6 Month | Ear Area (Right/Left) | 38 (46%) | 826/833* | 19.5/18.6 | 45 (54%) | 893/901* | 17.9/17.1 |
| Age (days) | 182 | 1.3 | 181 | 1.2 | |||
| Weight (kg) | 6.9* | .16 | 7.7* | .15 | |||
| 7 Month | Ear Area (Right/Left) | 40 (45%) | 820/845* | 19.9/18.9 | 49 (55%) | 922/916* | 18.0/17.1 |
| Age (days) | 208 | 3.5 | 203 | 3.2 | |||
| Weight (kg) | 7.1* | .15 | 8.0* | .14 | |||
| 8 Month | Ear Area (Right/Left) | 14 (40%) | 832/832* | 38.5/37.7 | 21 (60%) | 941/946* | 31.4/30.8 |
| Age (days) | 240 | 1.9 | 237 | 1.6 | |||
| Weight (kg) | 7.4* | .26 | 8.2* | .21 | |||
| 9 Month | Ear Area (Right/Left) | 5 (33%) | 855/840 | 44.5/41.0 | 10 (67%) | 936/920 | 31.4/29.0 |
| Age (days) | 271 | 2.9 | 270 | 2.1 | |||
| Weight (kg) | 7.5* | .50 | 8.9* | .35 | |||
Of the 227 participants enrolled, 161 infants (71%) had completed four or more visits, while 48 infants (21%) were lost to follow-up after the enrollment visit. Due to the COVID-19 pandemic, in April 2020, all human subjects’ research in Lusaka was halted by the Ministry of Health. The suspension of these research activities explains the dip in cohort retention at month 5 and 9 for the 6-day and 14-week cohorts respectively (Figure 1).
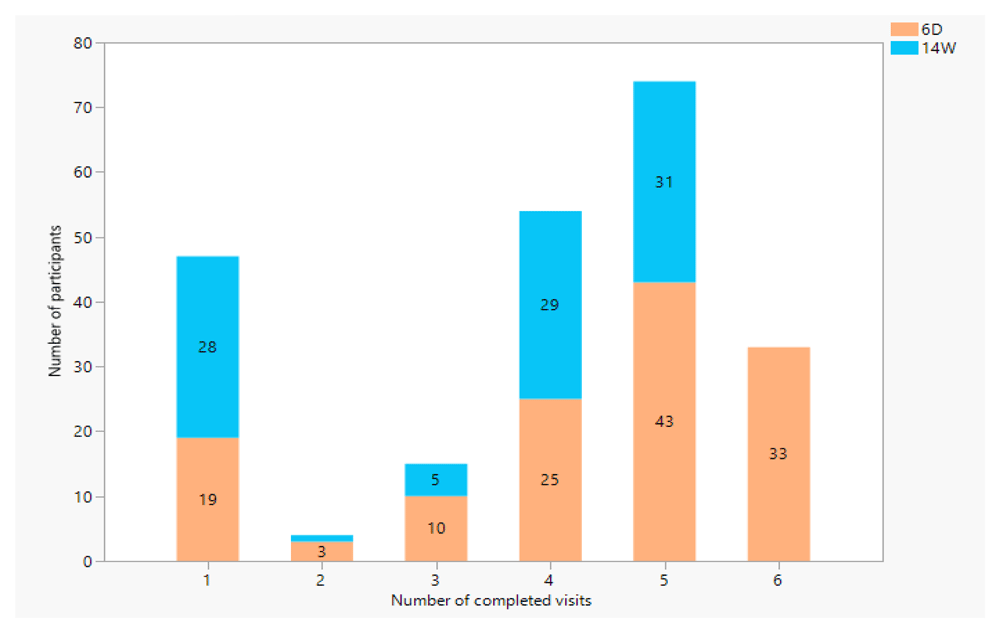
Those enrolled on their 6 Day vaccination in orange, those enrolled on their 14 week vaccination visit marked in blue.
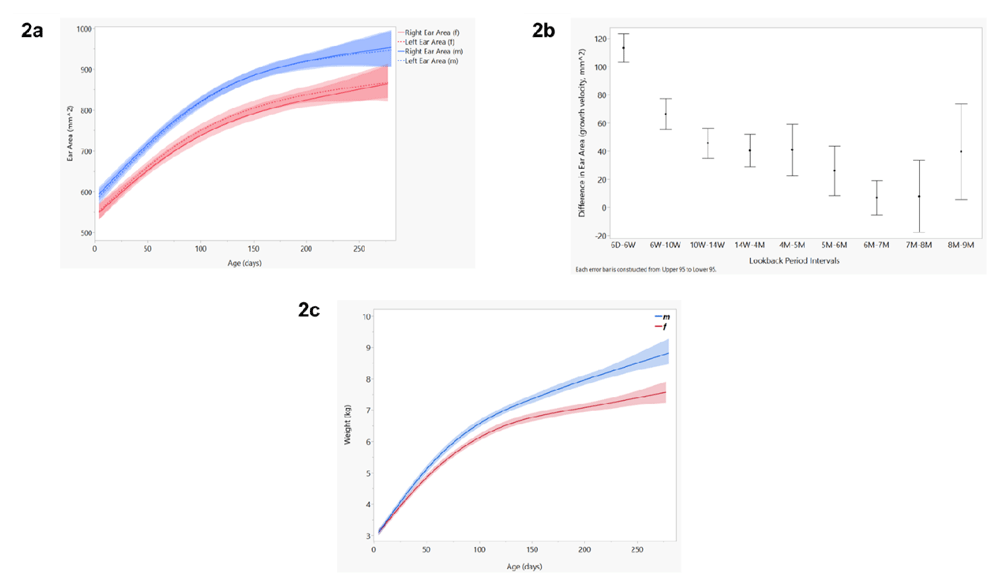
Figure 2a shows the relationship between ear area (mm2) and age (days), with blue representing the left and right ear area for males and red for females. These cumulative growth curves were smoothed using a cubic spline bounded by 95% confidence intervals. Figure 2b shows the relationship between growth velocity (change in ear area) and chronologically paired visits (look-backs). The mean growth velocity is displayed as a dot bounded by 95% confidence intervals. Figure 2c shows the growth chart of our cohort (weight by age) grouped by sex, using a cubic spline bounded by 95% confidence intervals.
Data show a consistent increase in ear area over time, with similar growth among boys and girls and between the left and right ears. As predicted, the increase in growth with time appears most pronounced in the early months. Table S1 in the extended data section also highlights the shifting number of participants who could be sampled at different time points, and therefore that the statistical precision of later comparisons will vary13. Mean weights between males and females were similar at 6 days. By 6 weeks, males weighed more than females (p<0.05), with this trend continuing through all later visits (6 weeks through 9 months). On average, left and right ear area was significantly larger in males from 6 days through 8 months.
We define ear growth as cumulative growth (ear area), velocity of growth (change in ear area), and directionality of growth (change in radial C measurements) over time (see the Methods section). Figure 2 shows three different growth charts from our longitudinal dataset, grouped by sex (color): a) right and left ear area (mm2) by age (days); b) change in ear area across a series of pairwise look-back periods; and, for comparison with a well-accepted anthropometric scale, c) weight by age for the same infants.
As can be seen, the slope for growth is maximal during the first few months of life, before leveling off at around 5–6 months of age.
Further analysis using a series of chronologically paired t-tests show that the change in ear area between visits is significant until 6 months (p < 0.001), whereafter growth velocity is no longer statistically significant (Figure 2b). This follows an inverse trajectory to cumulative growth, with largest growth occurring early (6W-6D, and 10W-6W), becoming asymptotic 6 months and above. It should be noted that cohort retention drastically dipped at 9 months. We included 9-month data in our analyses, however the precision of these comparisons are low due to small sample sizes (i.e. for 8–9 month look-back, we had only seven infants still in the cohort).
Growth was roughly symmetrical between left and right ear areas. Conversely, the ear growth curves for male and female babies differed significantly, with males having larger ears on average at all time periods (Figure 2a).
The data also emphasize the substantial variability in ear areas across the cohort such that the range of variation present at the six-day visit overlaps with some areas measured at 9 months. This is to say that some babies are born with very large ears and some with very small ears, but all tend to increase in size with time in a predictable way, particularly during the first six months.
Weight gain is significant between all look-back period intervals, and steadies to between 0.3 and 0.5 kg per month in later visits (Table 1). While the relationship between ear growth velocity and weight gain looks linear over the first 9 months, this analysis is weakened due to limited data in later visits. We predict that weight gain continues past 9 months, while growth in ear area remains asymptotic close to zero (Figures S1)13.
To explore directionality of ear growth, we examined radial C measurements on a subset of 90 participants from our study. C measurements were taken from a common anchor point on every ear (see the Methods section), where C1 measures from the anchor point to the top of the ear, C7 the width of the ear, and C13 from the anchor point to the bottom most point on the ear lobe. Figure S2 in the extended data section shows three of these measurements, plotted over time (C1, C7, and C13) for both left and right ears. These show that C7 (width of the ear) and C13 (dropping of the ear lobe) drive the growth, whereas C1 has little to no change over time13.
In our prior published work, we presented matching rates from cross-sectional data sets where each individuals were repeatedly photographed7. Since all photographs were taken within several minutes of one another, it is reasonable to assume that growth is essentially zero. Those analyses address the question, ‘how well can we match photo 1 to photo 2, both taken at time X?’. Using a variety of computer science techniques, we were able to achieve nearly perfect matching rates, including in infants.
However, by definition, these cross-sectional analyses do not assess the impact of ear growth over time, which is what the following analyses address. To do that the problem can be restated generally as, ‘how well can we match photo 1 at time X to photo 2 at time X+n?’, where n can vary reflecting the time between the two photographs.
Earlier tests using cross-sectional datasets achieved high recognition rates with the right mix of pre- and post-processing techniques7. Access to a longitudinal dataset allowed us to test the algorithm’s performance when matching images from later visits to images from earlier visits (look-back periods), which is a close approximation to how the tool would work in a real-world setting. The tests were performed on the Android implementation using left vertical ear images. Due to the drop-off in cohort retention between visits (Table S1, Extended Data), the number of participants with data for each visit varies. Because of this, each look-back test has a specified number of participants (n), looking for a match within a dataset of specific size (database n) (see the Methods section)13.
Results of these look-back periods, along with the number of participants for each test, are shown in supplementary tables (Tables S2a-S2i, extended data)13. Figure 3 summarizes the recognition rates between pairwise comparisons of all potential look-back intervals created by the two sub-cohorts (those enrolled at 6 days and followed for 6 months and those enrolled at 14 weeks and followed for 6 months). For example, the purple line at the top left of the graph provides the match rates for 9 versus 8 m, 9 versus 7 m, 9 m versus 6 m through 9 m versus 14 weeks, which was the first time point for that sub-cohort.
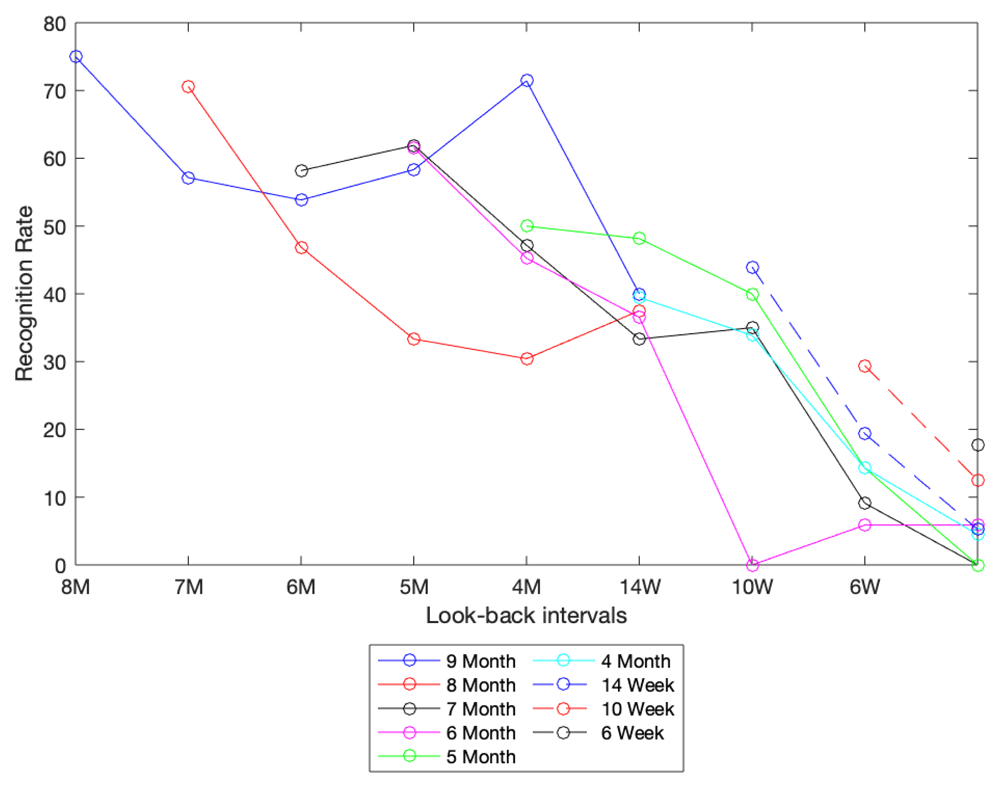
This graph shows results from various look-back tests. The color of the line signifies the starting point for each look-back test, while the x-axis represents the point in time being looked back to. For example, the solid red line represents a cohort of infants at 8 months. Each data point in this line represents the recognition rate (as a percent) for this cohort looking back to all data stored in a visit-specific database (specified by position on x-axis).
Accepting that these data are somewhat noisy due to variations in sample size at each time point, these results are broadly consistent with our theory that growth should adversely impact matching accuracy, and that growth velocity, being maximal earlier in life, has an additional impact on matching rates. Specifically, we observe a more rapid decline in matching accuracy in the pairwise comparisons from 4 m and below than 14 weeks and above. These results focus our attention on the younger age group as the key challenge in the ear biometric system and support our a priori assumption that growth of the ear is a key determinant in matching accuracy.
The results from our look-back period analysis made clear that improvements to the SEARCH algorithm were needed to move towards our ultimate goal of creating a robust identification system that could be used in early infancy. Our results to this point suggest that matching after 6 months of age is feasible, but the poor performance below 6 months remains challenging. While this represents an important advance over fingerprint technology, which has struggled to identify infants and children aged under 5 years, the first 6 months are an important period in an infant’s life where much longitudinal care occurs. We therefore focused on this age group
In our earlier published experiments, image concatenation proved to be a very powerful approach to improving matching accuracy7. Therefore, we conducted a series of experiments designed to test the effect of concatenation within the current matching algorithm as opposed to switching to a new matching algorithm. Concatenation is a technique for combining data from multiple images of the same object (in this case ears from a given individual) to improve the signal to noise ratio in matching experiments. This can be done by combining two images of the same ear at the same time, or the right and left ears (with one flipped digitally to create its mirror image), or combinations of the above taken at adjacent visits in time. In our prior work, we demonstrated that concatenation significantly improved matching rates in cross-sectional analyses. Here we apply this technique to the longitudinal case.
Configuration one: concatenating left and right ear images from the same visit. The first configuration involved concatenating multiple images taken during the same visit. For example, 9 M to 8 M involved concatenating the 9-month left vertical and right vertical descriptors before matching them against a database of 8 month left vertical and right vertical descriptors. In both cases, the right-hand image was flipped to create a pseudo left image prior to concatenating with the true left. In essence, mimicking a situation where an image is taken of each ear on each visit. The resulting identification rates (Tables S3a-S3i, extended data) show a marked improvement over the baseline – initial look-back period analysis (see Figure 4(i))13. The later tests (9 month, 8 month and 7 month) going as far back as the 5 month look-back show this improvement when compared with the baseline. In the baseline experiment, the identification rates ranged from a maximum of 75% to a minimum of 33.3% in that range while configuration one produced a range of 100% to 55.6%.
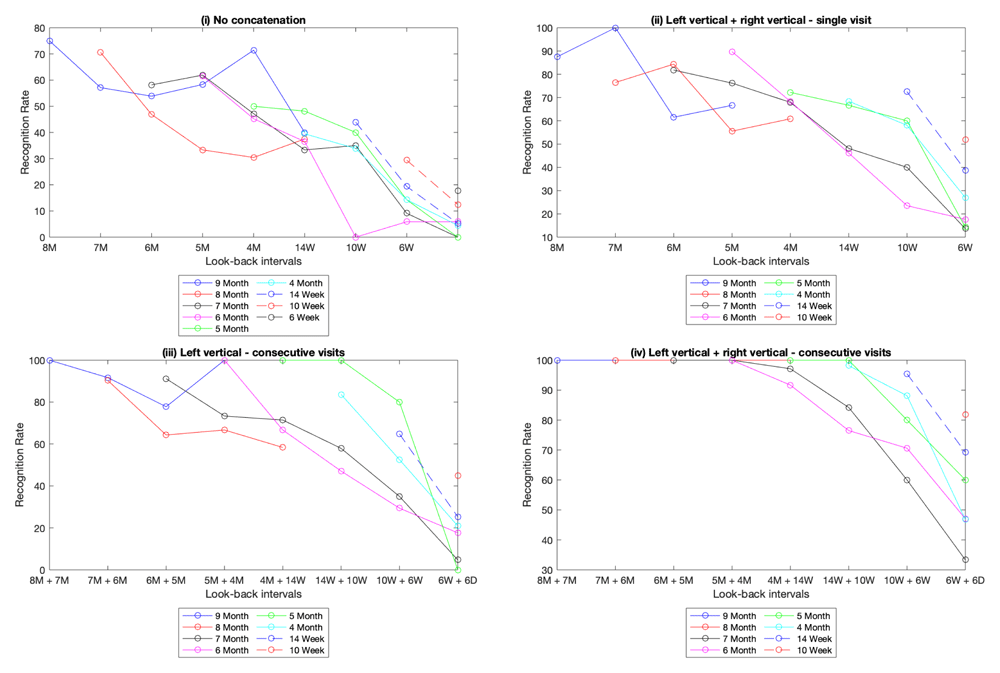
This set of graphs shows the look-back performance under various concatenation configurations. Graph (i) is the baseline, with no feature concatenation. The result of concatenating the left and right ear features are depicted in graph (ii). Graph (iii) is the result of concatenating the left ear features from two consecutive visit dates. Lastly, graph (iv) is a combination of the strategies in (ii) and (iii), the left and right image features from two consecutive visits are concatenated.
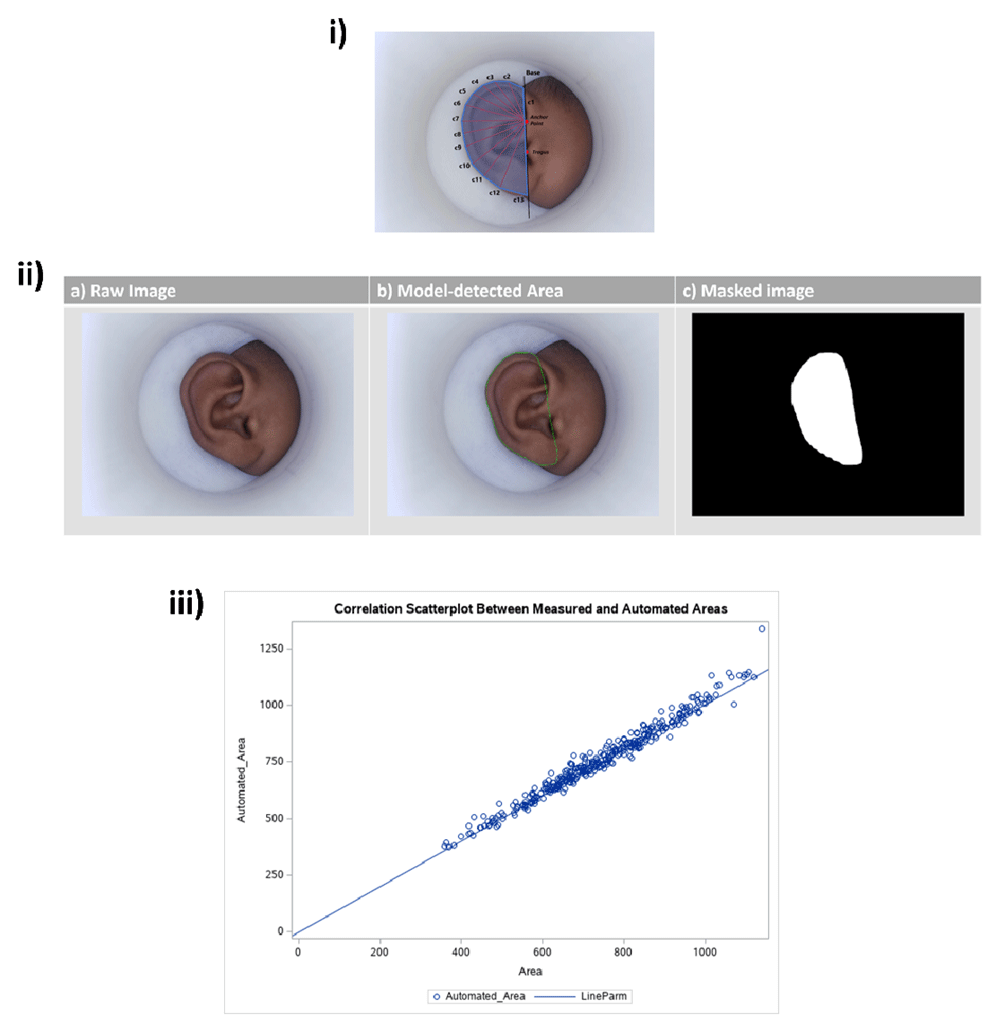
Figure 5 shows the method for manual annotations (5i), the automated area detection model (5ii), and how these two methods compare (5iii). Figure 6a shows manual measurements taken using MATLAB. Annotated features include the base line (the black line through the anchor point and the point tangent to the tragus), each of the radial measurements (red lines, c1-c13), and the polygon generated to calculate ear area (blue). These manual annotations were taken on a subset of images from our longitudinal dataset and were used to train a Faster R-CNN to automatically detect ear area. Figure 6b shows the input and output of the trained model, where (a) shows the raw image as input into the model, with outputs of (b) the detected region defined as ear area, and (c) the black and white masked area used to compute the area measurements. Finally, to justify using automated area measurements for the entire dataset (saving time and resources), Figure 6c shows manually measured area vs. the automated area measurements for the subset of 90 participants that were manually annotated. Because of the strong correlation between the two, we moved forward with reporting all areas as automated areas.
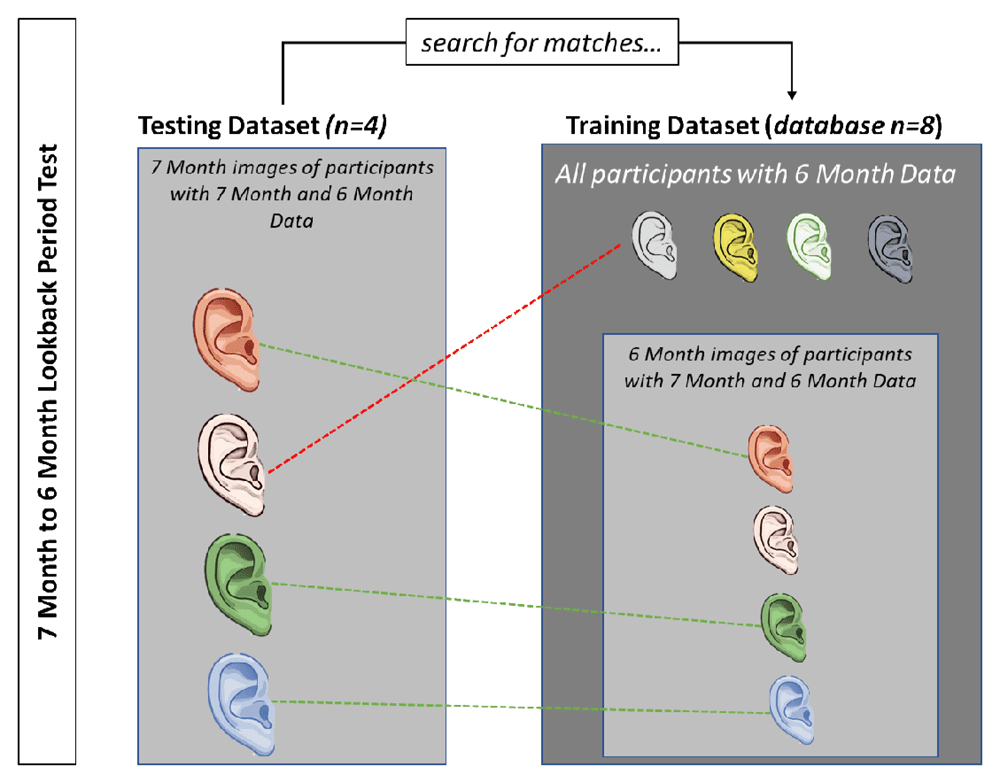
This figure depicts the process for matching using a simplified 7 month to 6 month look-back test example. In this example, there are 4 participants who have both 7 month and 6 month data (n=4). To perform the look-back test, we search for a match between the 7 month data and images in the 6 month database. The 6 month database includes these four participants plus four decoys, who do not have 7 month data. In this example, three of the four participants were correctly matched, resulting in a 75% recognition rate.
Configuration two: concatenating images across adjacent visits. The second configuration involved concatenating database images from multiple visits. In these tests, one source image was matched against a database of concatenated descriptors (usually made up of two descriptors from different visits). The results (Tables S4a-S4h, extended data) show an additional improvement across the board as a result of concatenating images at different stages of growth (see Figure 4(iii))13. Examining results of the 9, 8 and 7 month look-back tests up to the 5 month + 4 month test, the identification rates ranged from a maximum of 100% to a minimum of 66.667% compared with a range of 100% to 55.556% from configuration one.
Configuration three: concatenating every image from listed visits. Our third approach combines our methods from configuration 1 and 2. For each listed visit, every image (left vertical, left rotated, right vertical and right rotated) was concatenated on the database end. The four images were also concatenated to create the source descriptor. The results (Tables S5a-S5h, extended data) show a further improvement, with identification rates maxing out at 100% on the 9, 8 and 7 month look-back tests up to the 5 months + 4 months interval (see Figure 4(iv))13. The set of configuration strategies tested is by no means exhaustive, capturing a more varied set of images per participant during dataset creation would allow for different concatenation permutations to be tested. But more generally, these experiments show that it is possible to improve lost matching accuracy through software enhancements.
Our analysis demonstrates that ear growth follows a stereotypical pattern, with maximal growth during the first few months of life, eventually becoming asymptotic after 6–7 months of age. Unsurprisingly, matching rates were generally excellent when considering pairwise look back periods in infants older than six months but fell in younger infants. This loss of accuracy is a consequence of cumulative growth and of growth velocity but can be compensated for using basic tools of computer vision.
Based on the data presented above there is clear potential for ear biometrics to be a viable solution to patient identification in an infant population, where fingerprinting, iris scanning, and facial recognition historically fail. In Zambia the transition to using SmartCare, an EHR developed for tracking and monitoring pediatric ART, has been fraught with numerous patient identification challenges such as card readers failing, hardware incompatibility, cards being lost, misplaced, or forgotten, and patients not being found via a database demographic search (using first, and surname along with dates of birth). In the event that a patient is unable to be identified, a new record is created for the patient. This results in duplicate records which take up time and space within the system, and often contain inaccurate or incomplete patient data. Additionally, when a patient is not found and linked to their previous record, the provider does not have access to the patient’s longitudinal medical data during the encounter.
To fully realize the benefits that would result from the use of an EHR, we aim to show that a gold standard biometric solution would improve on the identification rate and reduce the number of times a patient is unable to be linked to their medical record. This gold standard solution could be applicable in a wide range of areas such as with cohort management in clinical research projects and in tracking and identification of refugees or displaced populations. It could also be used to link mobile clinics to a centralized EHR.
Though we have shown that ear biometric identification has the potential to be a reliable means of patient identification in an infant population, there are limitations of note. The first is that below 6 months, the SEARCH platform shows a steep drop-off in performance. Although we have been able to retrieve some identification accuracy lost, the pre-6 month age range is still a challenge. We are confident that with a larger cohort of infants, and more data, we will be able to test additional improvements for this younger age-range. Testing and iterative improvements of SEARCH using a larger, infant cohort focused on these younger age groups is the first of many next steps we propose.
The ongoing COVID-19 pandemic brought our data collection process to a premature end. This resulted in a much smaller dataset than initially envisioned. Though the resulting dataset was still large enough for us to notice the loss of performance in participants before the 6-month visit, in continuation of this work, we intend to test the SEARCH tool on a much larger cohort. A larger number of participants will assist in proving the viability of the tool. Taking more images per participant will also allow for more permutations of concatenation to be tested. Thus, another next step is to test SEARCH in real-time on a much larger database (thousands of people as opposed to hundreds).
Though funding for SEARCH has ended, we are proposing continuation of this work via an NIH R01 grant that will allow us to improve performance of the algorithm and test SEARCH as part of SmartCare (Zambia’s EHR for pediatric ART) in real-time across clinics in Zambia’s Southern Province. We are hopeful that SEARCH can be optimized and used to improve patient identification in infant populations, leading to improved continuity of healthcare.
Zenodo: Ear Datasets – Longitudinal https://doi.org/10.5281/zenodo.5676103
This project contains the following underlying data:
All right ear images from all participants across all visits in the longitudinal study. The name of the image follows the format: “patientID – weekofvisit”, where the week of visit is the grouping used for lookback period tests in this paper.
All left ear images from all participants across all visits in the longitudinal study. The name of the image follows the format: “patientID – weekofvisit”, where the week of visit is the grouping used for lookback period tests in this paper.
Zenodo: Extended Data https://doi.org/10.5281/zenodo.5675940
Includes a document that contains extended data tables and figures related to the paper.
Strobe checklist for “The impact of ear growth on identification rates using an ear biometric system in young infants”, https://doi.org/10.5281/zenodo.5676380
Zenodo: SEARCH Software https://doi.org/10.5281/zenodo.5676294
This database contains the python code for the automated ear area detection model, and the OpenCV code for the Android Testbed used to simulate all lookback period analyses done in this paper.
| Views | Downloads | |
|---|---|---|
| Gates Open Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with Gates Open Research
Already registered? Sign in
If you are a previous or current Gates grant holder, sign up for information about developments, publishing and publications from Gates Open Research.
We'll keep you updated on any major new updates to Gates Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)