Keywords
cholera, surveillance, outbreaks
cholera, surveillance, outbreaks
Cholera remains a significant global health challenge, disproportionately affecting populations with limited access to water, sanitation, and hygiene (WASH).1 In recent years, cholera outbreaks have continued to appear in both endemic regions and areas that have not recently reported cases, despite heightened cholera control activities.2–5 Many of these recent outbreaks, particularly in Africa, have been marked by high case fatality risks (CFRs), straining public health and healthcare systems and increasing the demand for critical resources such as oral rehydration solution (ORS) and oral cholera vaccine (OCV).6
Accessibility to continuous cholera surveillance data is critical for improving our understanding of cholera epidemiology and developing data-driven control strategies. Case-based time series can contribute to analyses on long-term patterns in transmission dynamics, endemicity, and seasonality,5,7 identify early warning signals for timely outbreak detection, and anticipate resource needs for outbreak response.8–10 These data can also be leveraged in scenario modeling to assess the impact and cost-effectiveness of different control activities like implementing diagnostic testing in surveillance, OCV campaigns, or WASH interventions.10–15 Such models can also be used to set public health targets or identify benchmarks in target product profiles (TPPs) for diagnostics and vaccines.16 Despite the significance of high-quality surveillance data in guiding these control efforts, cholera surveillance has been neither systematically reported nor widely available.17–23 Weekly cholera surveillance data for Africa has only begun to be reported by the World Health Organization (WHO) in 2023, and more historical data are critically needed to advance research and policy on cholera control strategies.24
Here, we present four historical datasets of case-based surveillance of suspected cholera at national and subnational levels across Africa from 2010 to 2023: a weekly continuous suspected cases dataset and a subset of the weekly dataset representing only cholera outbreak periods from completely public data sources (i.e., public surveillance dataset and public outbreak dataset), and two analogous datasets from a mix of public and non-public data sources with masked location information (i.e., location-masked surveillance dataset and location-masked outbreak dataset). The public datasets are accompanied by a linkable dataset of shapefile geometries. All data products were derived from a cholera incidence database that integrates surveillance data from diverse sources, including situation reports, linelists, and other public records. By alleviating the gaps in non-systematic cholera surveillance and outbreak reporting in Africa, these datasets contribute to the global efforts to mitigate the burden of cholera and strengthen outbreak preparedness and response capabilities.
Cholera incidence data were compiled from a combination of public and non-public sources within the continuously updated Cholera Taxonomy database (https://cholera-taxonomy.middle-distance.com/).25 To ensure the completeness and validity of the data in this database, systematic data entry and validation activities are conducted regularly. This includes a comprehensive data entry system that integrates surveillance data from diverse sources such as Médecins Sans Frontières and ReliefWeb, along with periodic data sweeps from authoritative public sources such as the UNICEF Cholera Platform, WHO and the WHO Regional Office for Africa to ensure the inclusion of high-quality surveillance data, such as weekly subnational observations.24,26,27 Additionally, the database undergoes regular updates to replace outdated records with the latest situation reports.
A standardized system of location hierarchies and shapefile geometries is also maintained in Cholera Taxonomy. Location auditing was performed systematically to verify location names (called “Locations” in the database), a location’s level in the administrative hierarchy, and location boundaries. Locations were linked to shapefiles for the time period that a given boundary was valid (called “Location Periods” in the database), thus enabling documentation of changing boundaries over time. Shapefiles were sourced primarily from centralized and curated data sources, including shapefiles The Humanitarian Data Exchange, Global Administrative Areas (GADM), and geoboundaries.28–30
Daily and weekly cholera incidence data across Africa from January 1, 2010 to December 31, 2023 on suspected cases, confirmed cases, and deaths were extracted from the Cholera Taxonomy database in November 2023. These data were then processed into weekly consecutive time series— hereafter, surveillance datasets —using functions in the OutbreakExtractR package (release v1.0, https://github.com/HopkinsIDD/OutbreakExtractR/tree/main) ( Table 1, Figure 1). In brief, daily cholera data were aggregated to a weekly level and combined with the original weekly cholera data. Weeks with duplicate observations were averaged and observations with different epidemiologic week starting days (Sunday versus Monday start) were shifted to the nearest week that matched the uniform start dates. Weeks with missing data in between the first and last reported observations and the eight weeks before and after the first and last reported observations were assumed to have zero suspected cholera cases (henceforth, “implicit zero observations”). Observation locations are available at country level (ADM0) down to third-level administrative unit scale (ADM3).
The columns describe the data processing functionality, OutbreakExtractR function name, and the specific data cleaning steps performed.
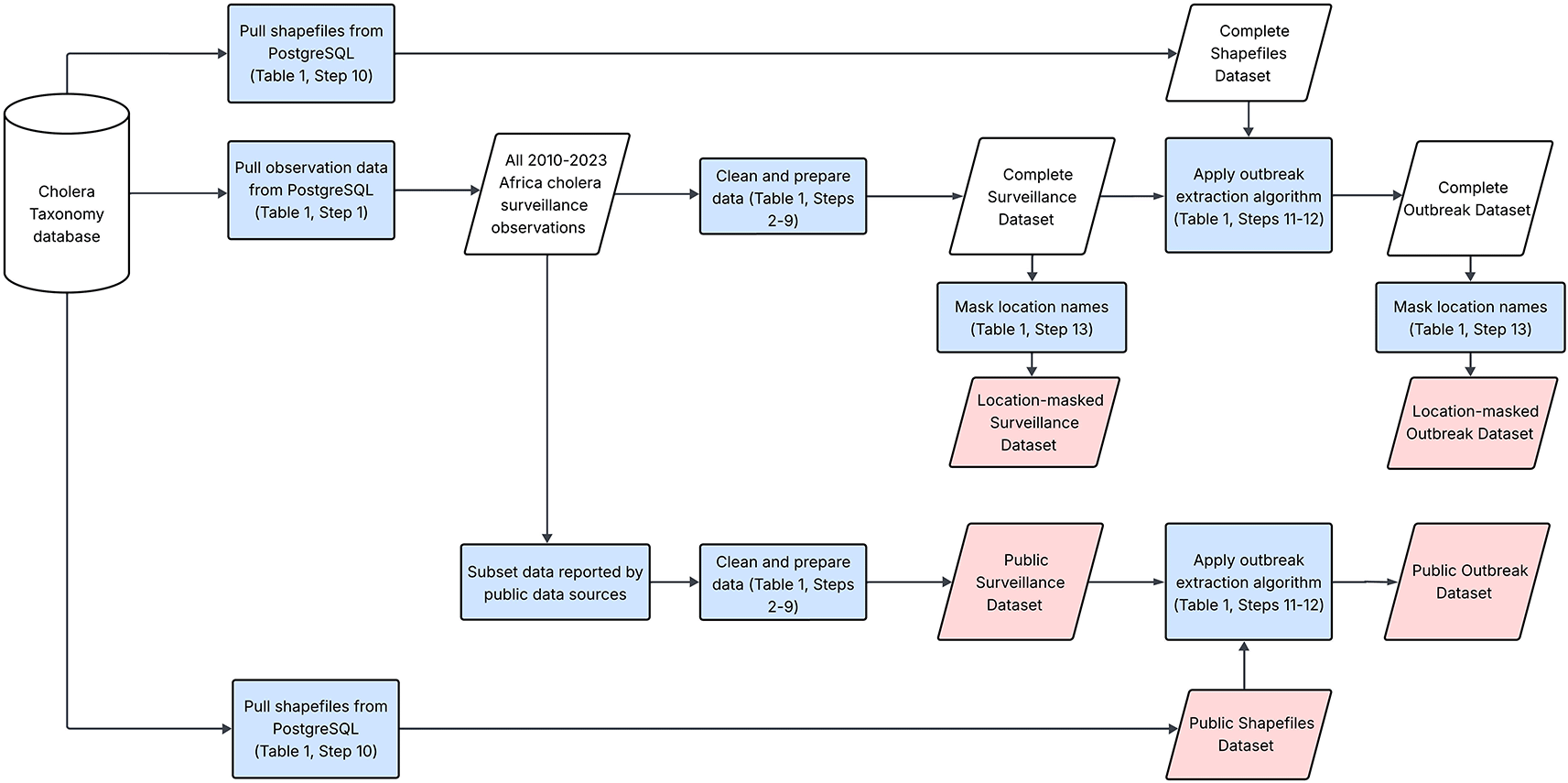
This figure illustrates the general workflow for pulling and cleaning data from the Cholera Taxonomy database. The cylinder represents the Cholera Taxonomy database, which contains global cholera surveillance data. Blue rectangles highlight data processing steps and parallelograms represent datasets. The pink parallelograms show the published data outputs.
Population data were essential for calculating outbreak thresholds.10 The spatial distribution of population estimates were obtained from the WorldPop 100 m by 100 m gridded dataset via the wpgpDownloadR R package, and the gridded estimates were scaled such that country-level estimates matched 2022 United Nations World Population Prospects projections when using geoboundaries shapefiles.30–33 The spatial distribution of 2021-2023 was assumed to be the same as that in 2020, as 2020 was the latest available WorldPop gridded dataset. Population estimates were calculated as the sum of the area-weighted overlap between grid cells and the location shapefile. Five locations with zero cases reported and an estimated population of zero were removed from the dataset.
A systematic and location-specific cholera outbreak definition was applied to the surveillance datasets to create the outbreak datasets (Step 12 in Table 1, Figure 1). The outbreak definition that was applied was previously described in Zheng et al. (2022), which analyzed cholera outbreaks in sub-Saharan Africa from 2010 to 2019.10 In brief, an outbreak began when the weekly cholera incidence rate surpassed the location-specific outbreak threshold, followed by at least two consecutive weeks of increasing incidence rates. An outbreak ended when the weekly incidence rate went below the outbreak threshold for two consecutive weeks and was followed by a four-week washout period that remained below the threshold. The outbreak threshold was defined as the location-specific average weekly incidence rate over the complete available dataset.
Outbreaks statistics were stratified by subnational scale (ADM1 to ADM3). These included: outbreak threshold, outbreak size (total cases during the outbreak), outbreak duration, time to peak week, proportion of suspected cholera cases reported during the peak week, weekly incidence during the peak week, early outbreak reproductive number (the average reproductive number over the first week of the outbreak), time to observing 50% of total cases (timecases50), outbreak attack rate (total cases per 1,000 population), and CFR. The outbreak peak was defined as the week with the maximum number of cases. We also calculated the population-weighted case-fatality risk for each spatial scale.
According to the Institutional Review Board (IRB) at the Johns Hopkins Bloomberg School of Public Health (BSPH), the surveillance and outbreak datasets constructed from the Cholera Taxonomy database were exempt (BSPH IRB No. 27682).
We prepared four time series data files for release. Two products are weekly consecutive time series and outbreak-specific time series of suspected cases from public data sources – the public surveillance dataset and public outbreak dataset, respectively ( Figure 1). These data are accompanied by a linkable dataset of shapefile geometries ( Figure 1). Columns are provided to enable users to retrieve the original source documents from the Cholera Taxonomy database website by entering the observation collection unique ID (OC UID) into the search bar.25
We also provide weekly consecutive time series and outbreak-specific time series datasets as derived from the complete set of Cholera Taxonomy data sources with masked location names – the location-masked surveillance dataset and location-masked outbreak dataset, respectively ( Figure 1). Locations were masked in these datasets as some data in Cholera Taxonomy were provided under data sharing agreements that prohibited sharing of individual or identifiable aspects of the data.
The public surveillance dataset includes 336,380 weekly incidence observations across 732 unique weeks from 2010 to 2023. Of these, 27.4% (92,160 observations) were implicit zero observations, 5.0% (16,909 observations) reported at least one suspected case, and the remaining observations were actively reported zeros. This dataset spans 2,336 unique African regions across multiple spatial scales, including 33 countries, 336 first-level administrative units, 1,781 second-level administrative units, and 187 third-level administrative units ( Figure 2). The location-masked surveillance dataset includes 1,259,495 weekly incidence observations reported in 4,161 unique regions in Africa. Among them, 21.8% (274,903 observations) were implicit zero observations while 5.1% (63,825 observations) reported at least one suspected case.
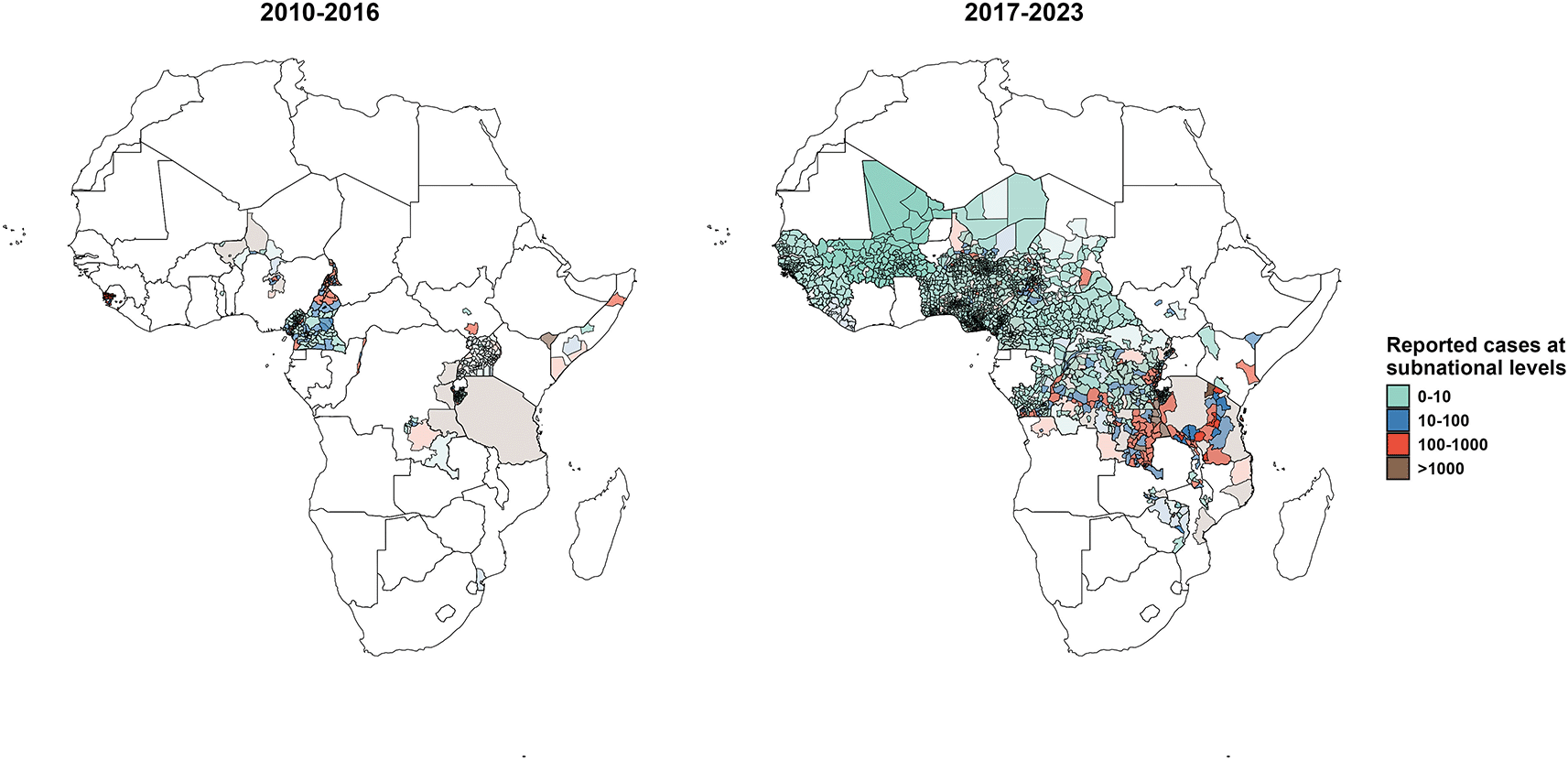
These maps illustrate the spatial distributions of reported suspected cholera cases across subnational administrative units in the public surveillance dataset. Data are represented for 2010-2016 (left) and 2017-2023 (right) and overlapping administrative units are layered such that larger units are in the background and smaller units are in the foreground.
Based on the public outbreak dataset, a total of 391 cholera outbreaks were identified in 279 unique African regions between 2010 and 2023, including 46 outbreaks at the national level, 109 outbreaks at the first-level administrative units, 218 outbreaks at the second-level administrative units, and 18 outbreaks at the third-level administrative units ( Table 2). According to the location-masked outbreak dataset, 1,668 cholera outbreaks were extracted in Africa from 2010 to 2023. 70 outbreaks were reported at the national level, 205 outbreaks were reported at the first-level administrative units, 1,028 outbreaks at the second-level administrative units, 337 outbreaks at the third-level administrative units, and 28 outbreaks in non-administrative regions ( Table 2).
This table presents key epidemic metrics for the public and location-masked outbreak datasets by different administrative reporting units.
While these datasets constitute one of the most extensive collections of cholera surveillance data in Africa from 2010 to 2023, there are several challenges. For one, we note that these datasets are based on reported suspected cholera cases and include data from multiple case definitions. Although suspected cases serve as the primary reported metric in cholera surveillance, the substantial variability in positivity rates among suspected cases and inconsistencies in case definitions may limit the ability of the datasets to accurately capture the true cholera burden.34 Given the disparate sources of data and reporting at multiple spatial scales, the dataset includes discrepancies and potential duplicate reporting when observations overlap in space and time. Further, gaps in surveillance and reporting and limited availability of weekly data mean that the dataset may not be completely representative of all cholera reports in Africa during this period. To alleviate these gaps, we assigned zero cases to weeks without reported data. However, comparison with outbreaks characterized in our previous outbreak paper, where “implicit zeroes” were not applied, suggested that this “implicit zero cases” assumption may lead to lower outbreak thresholds, larger outbreak sizes, and extended outbreak periods in some regions ( Table 4).10 Additionally, outbreaks occurring at the beginning or end of the analysis period may have been truncated when we applied the outbreak extraction algorithm to the 2010-2023 period. Despite systematic auditing of location names and shapefiles, the large geographic and temporal scales of the database pose challenges to ensuring the geographic accuracy in our datasets. Population estimates and therefore outbreak thresholds and attack rate metrics depend on the quality of the gridded WorldPop source we used, and are further constrained by the availability and validity of shapefiles. Population estimates after 2020 were derived by applying the 2020 WorldPop spatial distribution to country-level population totals for post-2020 years. While UN population data were used to scale national totals for all years, the absence of single-year WorldPop rasters beyond 2020 led to the assumption that the spatial distribution of post-2020 populations remained stable relative to 2020, which may not match reality.
External validity
We compared descriptive statistics from the location-masked surveillance and outbreak datasets to those reported in an independent study, Koua et al. (2025) on cholera outbreaks in the WHO African region (WHO AFRO) from 2000 to 2023.35 These statistics represented the number of WHO AFRO countries reporting cholera outbreaks per year and the annual case fatality risk ( Table 3). For the purpose of the table, we grouped outbreaks according to the year of outbreak start. As cholera outbreak definitions in Koua et al. (2025) were not systematically defined, we compared their counts to two metrics from our datasets – number of countries reporting at least one suspected cholera case in the location-masked surveillance dataset, and number of countries reporting outbreaks in the location-masked outbreak dataset. CFR definitions also differed between the two sources. Koua et al. (2025) appeared to report the total ratio of reported deaths and cases in a given year and we calculated the population-weighted average CFR across all outbreaks that actively reported death counts (including zero deaths) from our location-masked outbreak dataset.
This table compares the number of countries affected by cholera outbreaks annually and the annual CFRs between Koua et al. (2025) and the location-masked datasets. The number of countries with cholera death reporting, noted in parentheses in the fourth column, represents the subset of data used to calculate the annual population-weighted CFR in the location-masked outbreak dataset (sixth column).
When comparing the number of countries with at least one suspected case in the location-masked surveillance dataset and the number reporting outbreaks in Koua et al. (2025), there was little concordance between the two sources and no source reported systematically more countries with cholera ( Table 3).35 However, Koua et al. (2025) did systematically have more countries reporting outbreaks than our location-masked outbreak dataset. There were also differences in the reported annual CFRs between the two studies ( Table 3), but no source systematically reported higher CFRs.
Discrepancies in these metrics are due to different data sources, missingness, and outbreak extraction criteria. Most locations in our location-masked surveillance dataset were missing years of data between 2010 and 2023. Substantial data in the Cholera Taxonomy database could not be compiled to a weekly scale and were thus excluded from these data products. Limited data from the Integrated Disease Surveillance and Response (IDSR) system were present in the Cholera Taxonomy database (only 5 countries in the WHO AFRO region between 2006 and 2022), whereas this was the primary source of the Koua et al. (2025) cholera data.35 Further, there was limited weekly reporting of cholera deaths in Cholera Taxonomy, which meant that CFR could only be calculated for a subset of outbreaks. Another source of discrepancy is different methods for defining cholera outbreaks. Our dataset applied a standardized outbreak definition based on historical weekly incidence, while Koua et al. (2025) defined cholera outbreaks according to what was reported by the WHO event management system.35 Both approaches may be subject to missingness with different biases, and relative to the other dataset, our approach may particularly exclude outbreaks that are particularly small, short, or in cholera-endemic regions. We are not certain what biases may exist with regards to outbreaks recorded by the WHO event management system.
Internal validity
Data from 2010-2019 in the location-masked outbreak dataset was validated to our team’s previously published 2010-2019 African cholera outbreak dataset by comparing outbreak locations, start and end dates, and outbreak metrics.10 Outbreaks from the two datasets were classified into three types of outbreak pairs: 1) outbreaks with identical start and end dates (identical outbreaks), 2) outbreaks that started within 4 weeks of the original outbreak start date (outbreaks with similar start), and 3) other outbreaks in the same location with overlapping time periods (overlapping outbreaks).
We identified 702 outbreaks with identical start and end dates, 206 outbreaks with similar start dates, and 13 overlapping outbreaks. The outbreak metrics for outbreaks reported at the second-level administrative units in different categories are summarized in Table 4, showing similar distributions across all metrics and categories, and confirming the consistency and validity of this dataset. We also noted 78 outbreaks from the original dataset not found in our new dataset, and 485 outbreaks identified in the new dataset which were not reported in the original publication.10
This table compares key outbreak metrics from Zheng et al. (2022) and the location-masked outbreak dataset. Where appropriate, we reported the mean, median, and interquartile range (IQR) across all outbreaks in a given category.
Discrepancies between the two datasets may be explained by several factors. Since the original publication, we identified and processed new surveillance data for the 2010-2019 period, refined the data preparation procedure to include outbreaks spanning multiple administrative regions, and harmonized observations into standardized epidemiologic weeks across data sources. We also scaled population data to match annual, country-level UN population estimates, which led to modifications in outbreak thresholds, thus shifting potential outbreak timing. Further, we added a new data preparation step that added “implicit zero cases” to weeks without reported data. This change systematically lowered the outbreak threshold in many locations and enabled more locations to meet outbreak start and end criteria by mitigating the effect of data truncation on outbreak extraction. We anticipated that this change would generally increase the number of outbreaks identified and extend the duration of some outbreaks, which is what we observed ( Table 4).
According to the Institutional Review Board (IRB) at the Johns Hopkins Bloomberg School of Public Health (BSPH), the surveillance and outbreak datasets constructed from the Cholera Taxonomy database were exempt (BSPH IRB No. 27682).
Source code for OutbreakExtractR R package is available from: https://github.com/HopkinsIDD/OutbreakExtractR/tree/main. Archived software for OutbreakExtractR v1.0 is available from: https://doi.org/10.5281/zenodo.15319642. License: GPL-3.0.
| Views | Downloads | |
|---|---|---|
| Gates Open Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with Gates Open Research
Already registered? Sign in
If you are a previous or current Gates grant holder, sign up for information about developments, publishing and publications from Gates Open Research.
We'll keep you updated on any major new updates to Gates Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)