Keywords
Newborn screening, policy, sample stability, dried blood spots, storage conditions
Newborn screening, policy, sample stability, dried blood spots, storage conditions
Newborn screening is a public health initiative that tests infants shortly after birth for rare but treatable diseases. The screening process entails the collection of 4–5 drops of newborn blood by heel prick, typically within 24–72 hours of life. Newborn samples are collected onto filter paper and sent to accredited laboratories where the dried blood spots are used to screen infants for risk of developing diseases included in the laboratory’s screening panel. Although newborn screening is typically completed within the first few days of birth, secondary use of samples is not uncommon. Beyond provision of health care, residual dried blood spot samples may be used for quality assurance to improve existing tests and programs, used under legal warrant or court order, or used for biomedical or epidemiological research1,2.
Emerging secondary uses of newborn screening data include using screening profiles for biological modelling. For example, gestational age estimation algorithms based on a combination of newborn screening analytes and clinical covariates such as sex and birthweight have emerged as novel alternatives for accurately categorizing infants across preterm birth categories. Postnatal gestational age dating based on newborn metabolic profiles generated from dried blood spot samples provides the opportunity to establish preterm birth estimates3–5 for jurisdictions for which data on preterm birth are currently lacking or inaccurate due to bias in population sampling and non-standardized use of clinical preterm birth thresholds6. Given the breadth of possible secondary uses of newborn screening samples, it is important to understand the effect of storage conditions on newborn screening samples.
In this study, we sought to determine longitudinal changes in metabolic profiles derived from residual blood spot samples from a provincial newborn screening facility in Ottawa, Canada. The effects of longitudinal changes in metabolic profiles on the performance of gestational age estimation models as a result of storage were determined.
The data for this study were derived from a quality assurance project run through Newborn Screening Ontario (NSO), located at the Children’s Hospital of Eastern Ontario. NSO is the provincial program that coordinates newborn screening in Ontario, Canada, screening more than 145,000 infants each year for over 90 analytes and analyte ratios.
After testing at NSO, newborn dried blood spot samples from healthy infants are temporarily stored on-site at 21°C, after which they are sent to a secure off-site facility as part of the newborn medical record. These stored samples can be used for secondary purposes, including use for method development, method comparisons and transfer of screening thresholds.
Archival screen-negative dried blood spot samples collected over the course of 2016-2017, that had been stored for 2-, 4-, 6-, or 12-months after initial analysis were used for this study. As per standard newborn screening policy, initial analysis of all samples occurred within two weeks of collection. The sample set was enriched to include approximately 40–50% preterm infants by random selection of available samples from infants born ≥ or <37 weeks gestation. Eight 3.2 mm diameter circular samples were punched from each dried blood spot sample for first tier testing of each of the following analytes: hemoglobin profiles; 17α hydroxyprogesterone (17-OHP); thyroid stimulating hormone (TSH); a panel of 12 amino acids and 31 acylcarnitines; t-cell receptor excision circles (TREC); biotinidase activity; and galactose-1-phosphate uridylyltransferase activity. Hemoglobin profiles were determined by high performance liquid chromatography on a Bio Rad VariantTM nbs system; neonatal 17-OHP, and TSH were measured using a PerkinElmer AutoDELFIA® Immunoassays; amino acid and acylcarnitine analysis was performed by electrospray ionization tandem mass spectrometry (Waters TQ Detector); total TREC copy number was measured by quantitative polymerase chain reaction using a ThermoFisher Scientific Viia 7; biotinidase and galactose-1-phosphate uridyltransferase levels were measured using the Astoria-Pacific SPOTCHECK® Pro system. For each sample included in the study, analyses conducted at each storage time point were compared with the original baseline analyses for the same newborn.
Agreement between paired baseline and stored metabolic profiles. Descriptive statistics were generated for the cohort. All analyte and clinical variables were standardized to a larger Ontario reference cohort by subtracting the mean and dividing by the standard deviation of the reference cohort7. For each storage time point Pearson and intraclass correlation8 coefficients were calculated between paired baseline and stored sample analyte levels. Two-sided Wilcoxon paired tests were used to compare baseline and storage data. Boxplots were used to describe changes in each analyte from baseline to paired storage time point in standard deviation units.
Validation of metabolic gestational age estimation models. Our group has previously developed and validated gestational age estimation algorithms derived from newborn screening profiles and other clinical covariates3,7,9. Linear regression models were developed to estimate continuous gestational age, and logistic models were fit to classify infants as term (≥ 37 completed gestational age weeks) or preterm (<37 completed gestational age weeks). Published gestational age estimation models were developed and validated using metabolic profiles generated within the standard newborn screening timeframe3,7,9.
To determine the impact of delayed analysis and storage on the performance of gestational age estimation models, we externally validated the performance of our models in samples analyzed at baseline (time 0) and after 2-, 4-, 6- and 12- months of storage. Samples where secondary screening could not be completed due to insufficient sample volume were excluded from model testing. Model coefficient estimates from our previously published models7 were fixed and used to score each infant’s metabolic profile to generate an estimated gestational age. Root mean square error (RMSE) was used to evaluate model performance. The mean square error (MSE) was calculated as the average of the squared differences of each estimated gestational age compared to each actual (ultrasound-validated) gestational age. The RMSE, the square root of MSE, in units of gestational age in weeks, provides an intuitive measure of goodness of fit of the model. For logistic models, we measured area under the receiver-operator characteristic curve (AUC). The performance of each gestational age estimation model was validated as previously published7:
Model 1: containing only the clinical factors of infant sex, birthweight, and multiple birth (yes,no)
Model 2: Model 1 + newborn screening analytes and analyte ratios including acylcarnitines, amino acids and enzyme markers.
All analyses were conducted using SAS software version 9.410, and R version 3.3211.
A total of 307 samples were analysed for this study. 74 samples were procured 2 months after initial analysis; 77 at 4 months; 78 at 6 months; and 78 at 12 months. The majority (68.1%) of samples were obtained from infants with a birthweight of ≥2500g, and 52.8% of samples were from term infants (born ≥37 weeks gestational age). Newborn samples were collected earlier among term infants (63.3±117.1 hrs after birth) than preterm infants (81.4±142.6 hrs after birth). A summary of newborn characteristics is provided in Table 1.
Box plots depicting changes in standardized analyte concentration determined within one week of sample collection and after storage are provided in Figure 1–Figure 3.
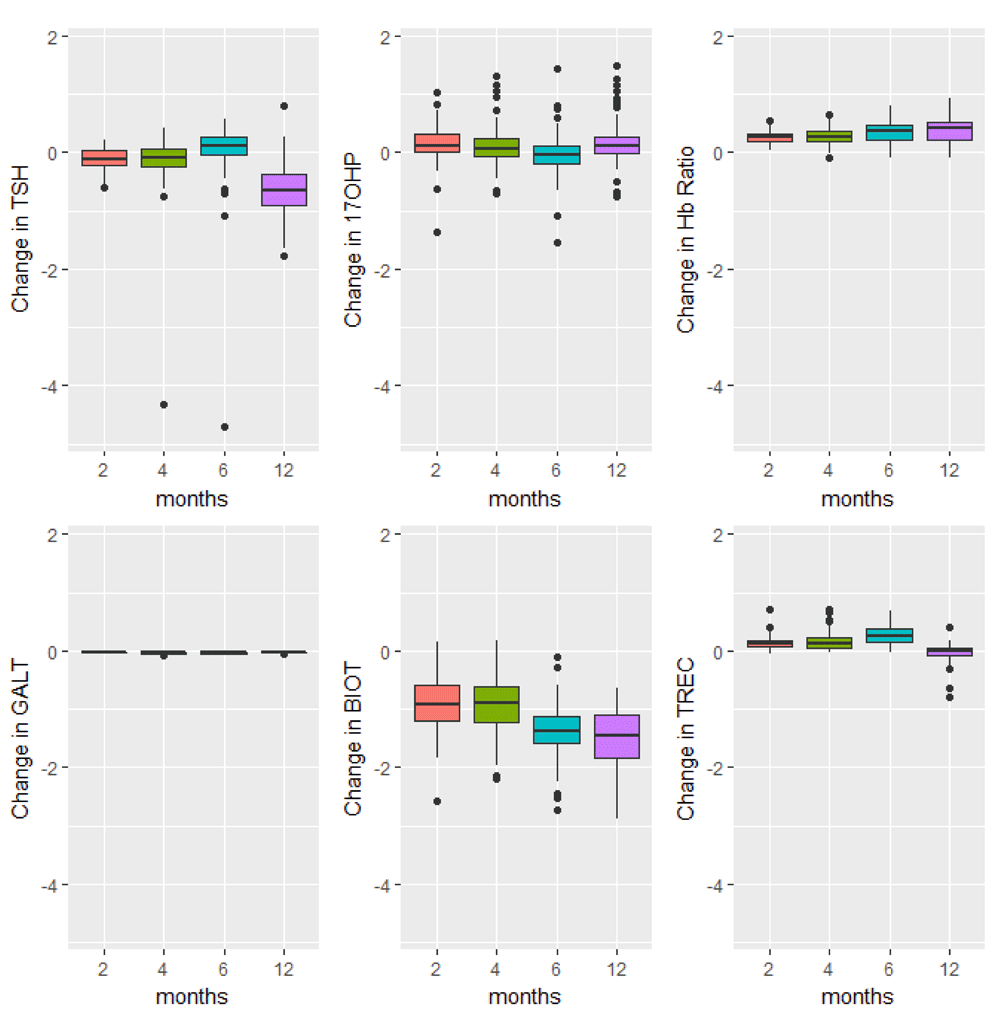
Boxplots of the changes in analyte levels after 2-, 4-, 6-, and 12-months of storage from baseline. The most variable marker in this category was biotinidase (BIOT). The lower whisker = smallest observation greater than or equal to lower hinge - 1.5 * IQR, and the upper whisker = largest observation less than or equal to upper hinge + 1.5 * IQR.
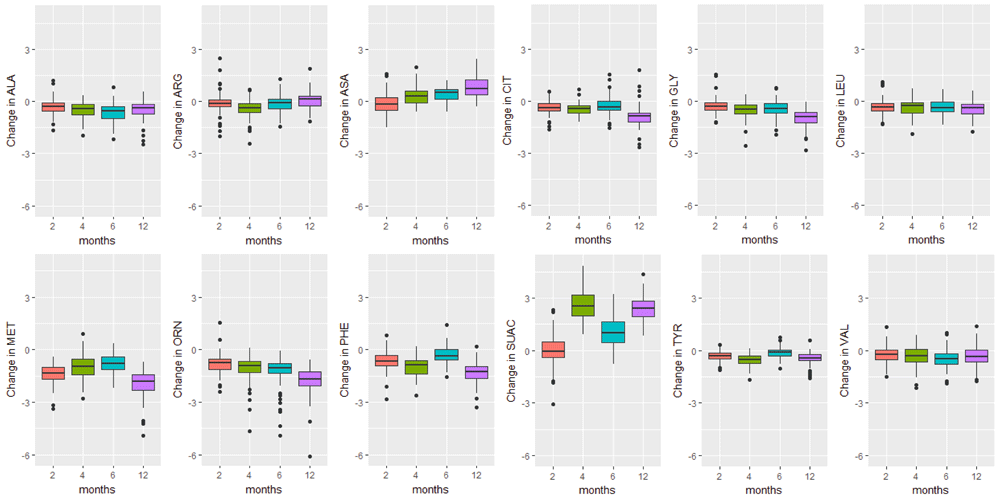
Boxplots of the change in analyte levels after 2-, 4-, 6-, and 12-months of storage from baseline. The most variable marker in this category was argininosuccinic acid (SUAC). The lower whisker = smallest observation greater than or equal to lower hinge - 1.5 * IQR, and the upper whisker = largest observation less than or equal to upper hinge + 1.5 * IQR.
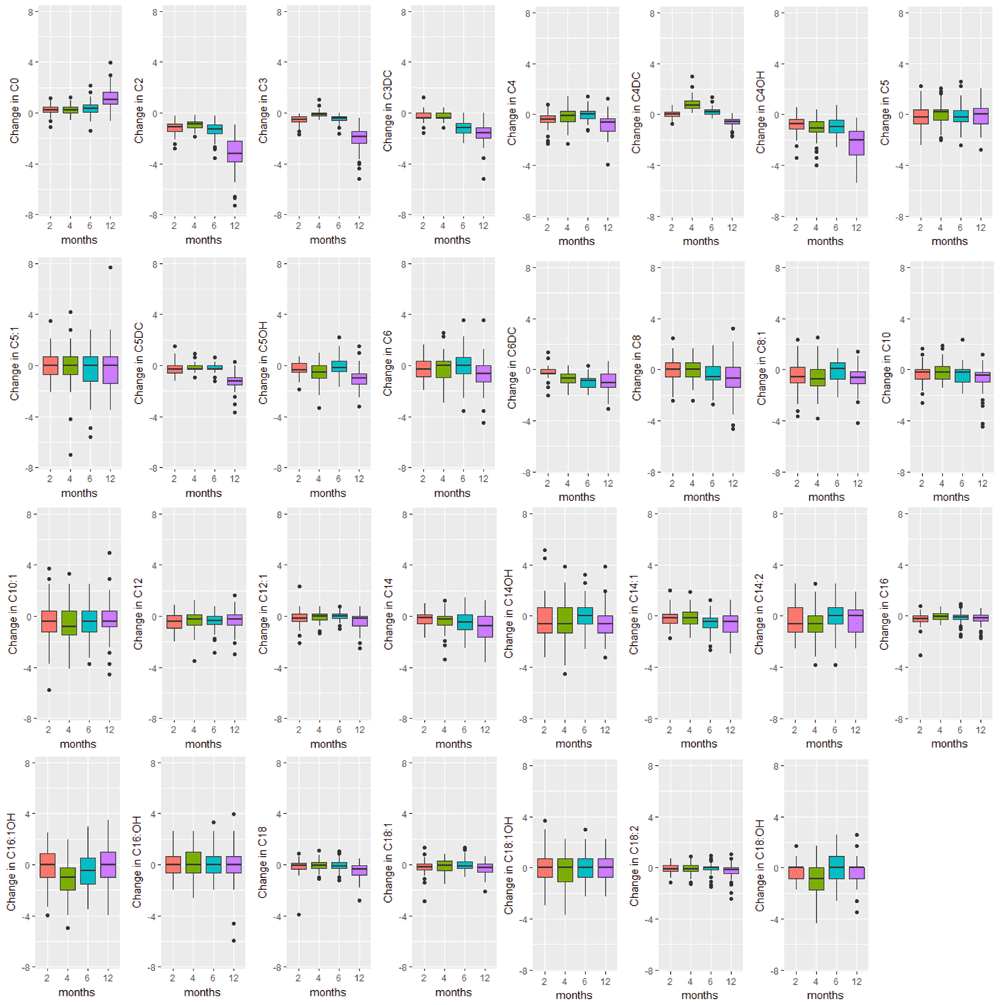
Boxplots of the change in analyte levels after 2-, 4-, 6-, and 12-months of storage from baseline. The lower whisker = smallest observation greater than or equal to lower hinge - 1.5 * IQR, and the upper whisker = largest observation less than or equal to upper hinge + 1.5 * IQR.
The majority of analyte levels (30 out of 48) were consistent at 2-months when compared to baseline levels (Pearson r≥0.8). 25 out of 48 of the measured analytes were highly correlated with baseline levels both 2-months and 4-months after collection (Pearson r≥0.8). Analytes exhibiting rapid degradation between initial analysis and 2 months after collection (Pearson r<0.5) were the amino acid argininosuccinic acid, and acylcarnitines C10:1, C14:OH, C16OH, C18:1OH, C18OH, C5:1. The endocrine hormone 17-hydroxyprogesterone (17-OHP) and relative levels of fetal hemoglobin peaks, taken by the ratio (HbF+F1)/(HbF+F1+A) were consistently the top two correlated analytes across all time points of analysis. Pearson and Intra-class correlations (ICC) with 95% CIs comparing baseline values to each time point of analysis, and Wilcoxon test results are provided in Supplementary File 1.
The performance of the linear regression models in providing continuous estimates of gestational age and correctly identifying gestational age within 1 and 2 weeks of ultrasound validated gestational age are summarized in Table 2 and Table 3, respectively. Application of linear models to fresh baseline samples revealed that a model including metabolic parameters (Model 2) consistently provided better estimates of gestational age than a clinical model limited to birthweight, sex and multiple birth status (Model 1). Metabolite models outperformed clinical estimates when metabolite data were derived from samples that had been stored for 2 months, 4 months and 12 months.
Whereas the performance of metabolite models was similar for data derived after 2 and 4 months of storage compared to paired baseline values (each within 0.04 weeks RMSE and 7% of the proportion of infants correctly classified within 1 and 2 weeks of ultrasound validated gestational age), results after 6 months and 12 months of storage were more variable. Metabolite data measured after 6 months of sample storage yielded gestational age estimates that were 0.24 weeks less accurate than estimates derived from fresh samples. Here, gestational age was correctly identified within 1 week for 21.5% fewer infants, and within 2 weeks for 3.1% fewer infants. After 12 months of storage, estimates were 0.1 week less accurate, and gestational age was correctly identified within 1 week for 7.9% more infants, but within 2 weeks for 7.9% fewer infants.
We also evaluated the capacity of published models to accurately categorize samples across dichotomous gestational age categories (term, ≥37 weeks gestational age; preterm, <37 weeks gestational age) by logistic regression (Figure 4). As with the linear regression models, Model 2 consistently provided more accurate estimation of gestational age at baseline (AUC0.968 [95%CI 0.945, 0.991]) and after 2-months (AUC 0.970 [0.909, 1.00]), 4-months (AUC 0.981 [0.940,1.000]), 6-months (AUC 0.995 [0.977, 1.000]) and 12-months (AUC 0.955 [0.876, 1.000]) of storage compared to estimates derived from Model 1. The incremental improvement in gestational age estimation from Model 1 to Model 2 was attenuated when samples had been stored for 6- and 12-months compared to when analyzed at baseline and after 2- or 4- months of storage. Logistic regression model performance metrics are provided in Supplementary File 1.
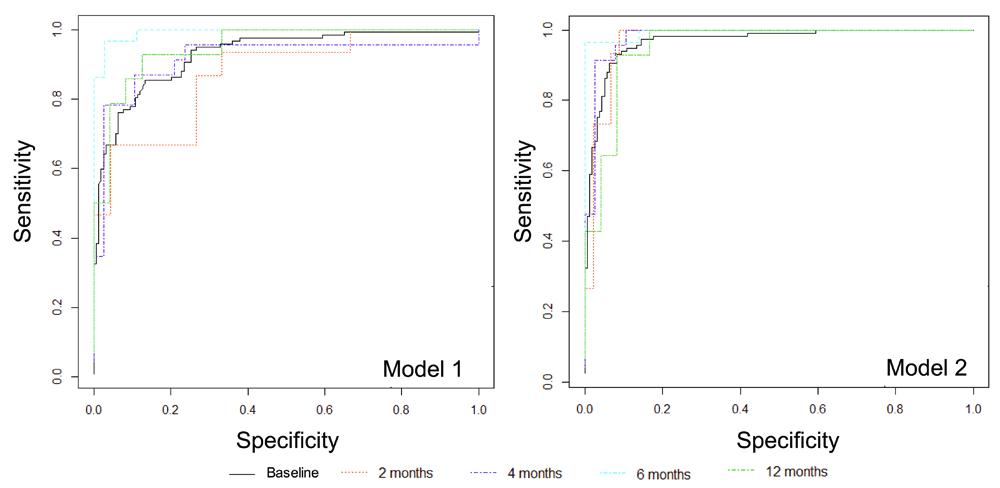
Metabolic models consistently provide more accurate estimates of gestational age, regardless of age of sample at the time of analysis, AUC all >0.95. Model 1, clinical variables only; Model 2, clinical variables + metabolite markers.
A comparison of ultrasound-validated preterm birth rates and algorithm-based estimates are provided in Table 4. In the overall cohort, 42.6% of infants were born preterm. The metabolic gestational age model, Model 2, provided better estimates of preterm birth compared to the clinical model when applied to baseline metabolic data (40.4% vs 34.9%), and also when applied to data obtained from stored samples. Misclassification was greatest when the metabolic model was applied to data captured after samples had been stored for 12-months (7.9% higher than ultrasound-validated preterm birth rate).
In this study we provide insight into the stability of residual newborn screening samples, and the impact of year-long storage on screening profiles. Hemoglobin profiles, amino acids, and endocrine and enzyme markers were largely stable from baseline to 6-months after collection. Stability of acylcarnitines was variable. Greatest changes in analyte levels were observed after 12-months of storage. As a result of shifts in newborn screening analyte levels secondary to storage, the performance of metabolic gestational age algorithms was poorest when sample analysis was conducted 12-months after collection. Our models consistently demonstrated strong performance for dichotomous classification of infants as either ‘term’ or ‘preterm’, although continuous estimates of gestational age were more affected.
In North America, state and provincial policies for the retention, storage and residual use of samples collected as part of newborn screening programs vary widely, ranging from one month to decades, to indefinitely1,12. In Ontario, Canada, samples are stored for 19 years before they are destroyed13. Protein, DNA and other potential targets from dried blood spots have been shown to be stable over many years14–17. However, the stability of individual analytes used to interpret newborn screening profiles after exposure to different storage conditions has been found to be largely variable. Available literature suggests a detrimental effect of high temperatures and high humidity on analyte concentrations. In a comprehensive study of the effect of storage conditions on 34 newborn screening markers, Adam et al. reported that all analytes were significantly reduced following 30-day storage at high temperature (37°C) or high humidity (>90%). The enzyme activities of GALT and BIOT were particularly susceptible, losing >60% of their initial activity when stored at high temperature, and >70% of their initial activities when stored at high humidity18. Our study also confirms variability of BIOT upon retesting. A study of the stability of amino acids and acylcarnitines over 8 days also found that high temperature and humidity increased the rate of analyte degradation, but that the analyte loss was greatest within the first 24 hours of exposure19.
Unique to this study is our evaluation of the impact of alterations in metabolic profiles over time on the performance of gestational age estimation models developed by our group. We have previously demonstrated the accuracy of such algorithms to estimate gestational age to within one week when applied to infants born in Ontario, Canada3,7,9. Gestational age algorithms such as those described here have the potential to provide reliable population-level estimates of preterm birth for jurisdictions where such data are currently lacking20. A 2017 review of the diagnostic accuracy of neonatal assessment for gestational age determination highlighted the challenges and limitations of postnatal neonatal scores which tend to overestimate gestational age in preterm infants and perform poorly in growth-restricted groups21. All metabolic algorithms published to date have been developed using ultrasound gestational age as the reference standard, are not subject to user variability and have been validated in small-for-gestational-age infant subgroups. Where the goal is to identify all preterm infants, models published by our group consistently demonstrate strong performance (AUC >0.9) for distinguishing infants as ‘term’ or ‘preterm’. In contrast, continuous estimates of gestational age may be of more use on an individual level or to robustly describe a population of interest. Although continuous models published by our group demonstrate favourable performance, what constitutes ‘acceptable’ performance relative to ultrasound or LMP reference standards is yet to be determined. Recent work has focused on streamlining and tailoring published algorithms for use across a range of infant subpopulations7. Validation of these models among various ethnic subgroups in Canada9 and in international settings has also yielded promising results. We are currently engaged in validating published algorithms in external newborn screening cohorts from the Philippines and China.
Where there are plans to implement this technology to generate preterm birth estimates in select low- and middle-income countries22, feasibility and scalability are important factors to consider. Data from this study can be used to determine the optimum length of storage of samples to manage program operations. Here, maintaining the integrity of blood spot samples prior to shipment to designated laboratories will be essential. In many parts of the world, including Sub-Saharan Africa and South East Asia, dried blood spot cards may be exposed to high temperatures and humidity during storage and transportation if immediate sample processing is unavailable. While current guidelines for newborn screening in Ontario are to analyze samples within 14 days of collection23, the present study suggests that room temperature, humidity-controlled storage should be sufficient to yield reliable metabolic data for gestational age dating after 2–4 months of storage. Refrigeration of samples, if feasible, stands to extend the viable storage duration24.
The strengths of this study include our use of a relatively large number of samples compared to other similarly structured studies, as well as our examination of four time-points over a wide interval of sample storage (2 to 12 months). Our use of a large number of samples of preterm infants - approximately 50% per time-point of analysis - permitted sound evaluation of gestational age estimation models. There are two notable limitations to this work. Although the study provides insight into the stability of newborn screening analytes stored in temperature and humidity-controlled conditions, we did not explore the effect of extreme environmental storage conditions on dried blood spot samples. Second, our study was limited to samples that had provided ‘negative’ screening results upon their first analysis. As it is unclear whether extremely low or high concentrations of analytes exhibit similar rates of degradation as analyte levels falling within the standard clinical reference range, as in our study, we cannot infer the stability of analyte concentrations from infants with congenital conditions.
In this paper, we have established that duration of storage, independent of temperature and humidity affect newborn screening profiles and gestational age estimates derived from metabolic gestational dating algorithms. When considering dried blood spot samples for secondary use, either for clinical or research purposes, care should be taken to store samples in temperature and humidity-controlled environments.
Data stemming from this project arose from a programmatic quality assurance initiative at Newborn Screening Ontario (NSO). As such, the authors do not have permissions to share the raw newborn screening data associated with this project. NSO is administered by the Children’s Hospital of Eastern Ontario (CHEO) and funded by the Ontario Ministry of Health and Long-term Care. NSO is committed to keeping newborn information, blood samples, and data arising from analysis safe and confidential. CHEO follows the following Canadian Standards Association privacy principles, which form the framework for Personal Health Information Protection Act, 2004 (PHIPA). PHIPA is Ontario's health information privacy legislation. It sets rules for how personal health information can be collected, used and disclosed. CHEO will not use or disclose personal information for purposes other than those for which it was collected, except with the consent of the individual or as required by law.
Individuals seeking a copy of the data presented in this study should contact [email protected], and the request will be assessed as per NSO’s data request and secondary use policies. For more information, please visit the NSO website: https://www.newbornscreening.on.ca/en/screening-facts/screening-faq (‘What happens when a researcher wants to access stored samples for research’); https://www.newbornscreening.on.ca/en/privacy-and-confidentiality.
NSO regularly seeks to improve existing testing. This quality assurance project sought to determine the stability of newborn samples after storage in agreement with the provincial terms of secondary use of newborn screening samples. As this was a quality improvement project, the requirement for ethics review and informed participant consent was waived by the Children’s Hospital of Eastern Ontario Research Institute.
| Views | Downloads | |
|---|---|---|
| Gates Open Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with Gates Open Research
Already registered? Sign in
If you are a previous or current Gates grant holder, sign up for information about developments, publishing and publications from Gates Open Research.
We'll keep you updated on any major new updates to Gates Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)